This blog is part of a series, AYLIEN NEWS API: A Starter Guide for Python Users. You can view the Jupyter Notebook learner document here.
The volume of news is overwhelming - traditional methods of media monitoring and news analysis are simply inadequate to deal with the constant stream of news data. Consequently, news intelligence has emerged as an automated means to track the news, empowering organisations to identify risks and opportunities and prompting decisive action where necessary.
In this blog series to date, we have looked at how AYLIEN’s News API ingests and enriches millions of news documents every day, providing cohesion to fragmented, unstructured data and making them easily searchable and readily processable. We’ve also looked at how Timeseries and Trends endpoints aggregate this data and help us quickly analyse large volumes of news.
In the final blog of the series, we’ll look at another API endpoint that aggregates individual stories to help us understand news coverage at scale - the Clusters endpoint.
What is News Clustering?
By its nature, news tends to repeat itself; multiple news stories will exist that report the same or similar topics. News events that gain traction can be covered multiple times, by many authors, by many sources, in many countries and in many languages while the lifespan of a news event means it could be in the public eye for merely a day or several weeks.
Using AYLIEN’s NLP enrichments, we can use machine learning to understand each article and effectively group documents that cover the same event or topic together in real time, regardless of the time of publication, source, or even the language articles are written in.
Why is this Useful?
This ability to segment and group the world’s news at a topic or event level enables our users to greatly improve the efficiency and accuracy of their applications and processes. Using clusters, we can identify topics and events that are gaining traction and increased coverage in the news, allowing us to perform automatic event detection and topic discovery which is particularly useful for monitoring breaking news.
It also enables us to deduplicate and summarise the news. Analysing news at scale is impossible manually - using clusters, users need only manually review one representative article at the heart of a cluster, allowing them to summarise and generalise large volumes of news across many clusters.
The Cluster Object
The cluster object is a JSON object that provides a cluster ID along with metadata about the stories in that cluster. Each cluster object relates the number of stories that make up that cluster, making it easy to discover and identify new or growing clusters. Typically the size of a cluster can be a strong indicator of a new or important event as it unfolds. Other filter options include source location, allowing you to build localized clustering searches with ease.
Story objects in turn will cite the cluster ID to which they belong. A story will only ever belong to one cluster and the relationship between the story and cluster does not change – it will not be reassigned to another cluster at a later time.
The cluster object also includes a representative story that best summarizes the event the cluster refers to. This is very useful, allowing us to understand in general terms what the cluster at large is about.
We can pull clusters directly from the Clusters endpoint. However, while we can define time, location and cluster ID parameters, because of the nature of clusters, we cannot define keywords or entity parameters in the fashion we normally would for other endpoints. Instead, we generally pull clusters using one of two methods, which we will discuss below.
Exploring Clusters Using the Trends Endpoint
We have noted above that we can pull clusters by defining the cluster ID, but how do we know what cluster IDs to query before we’ve queried them? We can use the Trends endpoint to filter clusters based on the stories contained within them. For example, you can filter clusters that contain stories with a specific category label, mention a specific entity, or even have a specific sentiment score.
Using the Trends endpoint, we can return the ID of clusters sorted by the count of stories associated with each cluster that meet our criteria. When we have our list of cluster IDs, we can then get the cluster metadata from the Clusters endpoint.
Retrieving clusters using the Stories endpoint
Another method of retrieving clusters is to use the Stories endpoint. First, we run a query to the stories endpoint and retrieve all the individual stories that meet our criteria. Then, we can iterate through the stories, extracting the cluster ID of which they belong. Finally, with this list we can query the Clusters endpoint to retrieve the cluster metadata we want.
Visualizing Clusters
Visualizing cluster data is a great way to quickly synopsize the news landscape and get a bird's eye view of your domain of interest. In the sample chart below, we used the Trends endpoint to identify all clusters relating to Citigroup bank. We then pulled the cluster metadata and plotted the clusters by their size on the y-axis and by the published date of their representative article on the x-axis. Finally, the clusters were also labelled with their representative article, giving us context on each cluster.
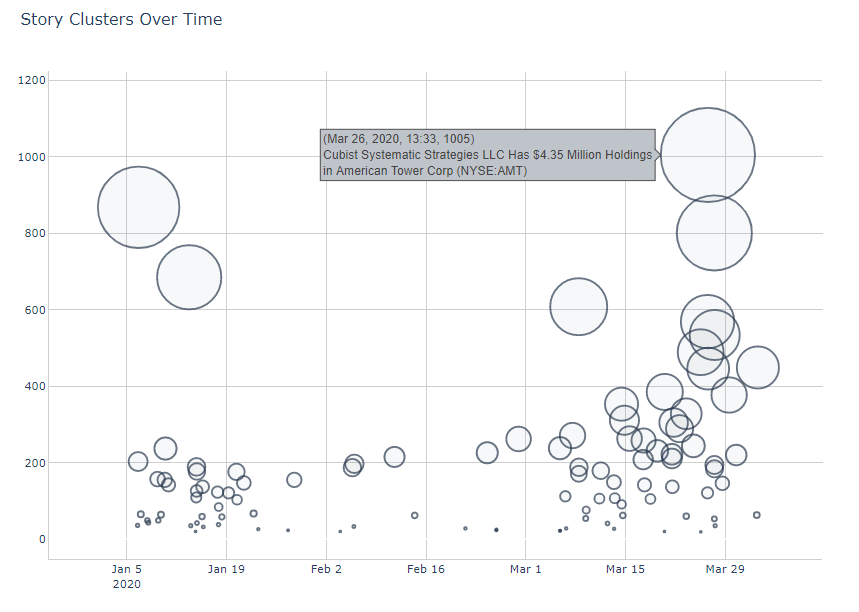
This powerful exploratory tool allows us to quickly visually scan and identify the most significant news clusters which Citigroup were referenced in.
Check out how we used clusters to investigate Country Risk and Natural Disasters.
Conclusion
In this blog series, we’ve given a general overview of AYLIEN’s aggregation and NLP enrichment process, the story object at the centre of our API and the various endpoints we can use to retrieve and analyse the news.
In the accompanying Jupyter Notebook, we show you how to get up and running quickly with AYLIEN’s News API as well as some helpful code to start wrangling the data in Python using Pandas and visualizing it using Plotly. This guide will arm you with a fundamental understanding and toolkit to help you start exploring the news in no time!
Now go get those insights!
This blog is part of a series, AYLIEN NEWS API: A Starter Guide for Python Users. You can view the Jupyter Notebook learner document here.
Other Blogs in the series:
Starter Guide 1: AYLIEN’s Story Object - a Primer on NLP Enrichment and How to Use it
Starter Guide 2: Refining Your News API Query
Starter Guide 3: How To Use The News API Timeseries Endpoint

Related Content
-
 General
General20 Aug, 2024
The advantage of monitoring long tail international sources for operational risk

Keith Doyle
4 Min Read
-
General
16 Feb, 2024
Why AI-powered news data is a crucial component for GRC platforms

Ross Hamer
4 Min Read
-
General
24 Oct, 2023
Introducing Quantexa News Intelligence
Ross Hamer
5 Min Read
Stay Informed
From time to time, we would like to contact you about our products and services via email.