This blog is part of a series, AYLIEN NEWS API: A Starter Guide for Python Users. You can view the Jupyter Notebook learner document here.
Other Blogs in the series:
Starter Guide 2: Refining Your News API Query
Starter Guide 3: How To Use The News API Timeseries Endpoint
Starter Guide 4: How To Use The News API Trends Endpoint
Starter Guide 5: Starter Guide 5: How to Use the News API Clusters Endpoint
News provides mission critical information for organizations. But the volume of news is overwhelming, resulting in missed events, misinformed decisions, and ineffective processes. AI-powered News Intelligence aggregates the world’s news content, using NLP to understand what matters to your business and delivering it to where you need it most.
At AYLIEN, we ingest over 1.2 million articles every single day. But high volumes of news content are of no use if we don’t know what it means at scale and we can’t find what we need, when we need it. That’s where AYLIEN’s Natural Language Processing (NLP) and document enrichment comes in.
Document Enrichment
Not only does AYLIEN collate huge volumes of news data, we transform millions of unstructured media articles into structured data every day in real time using Machine Learning and NLP. In other words, NLP makes it possible to understand exactly what each article contains.
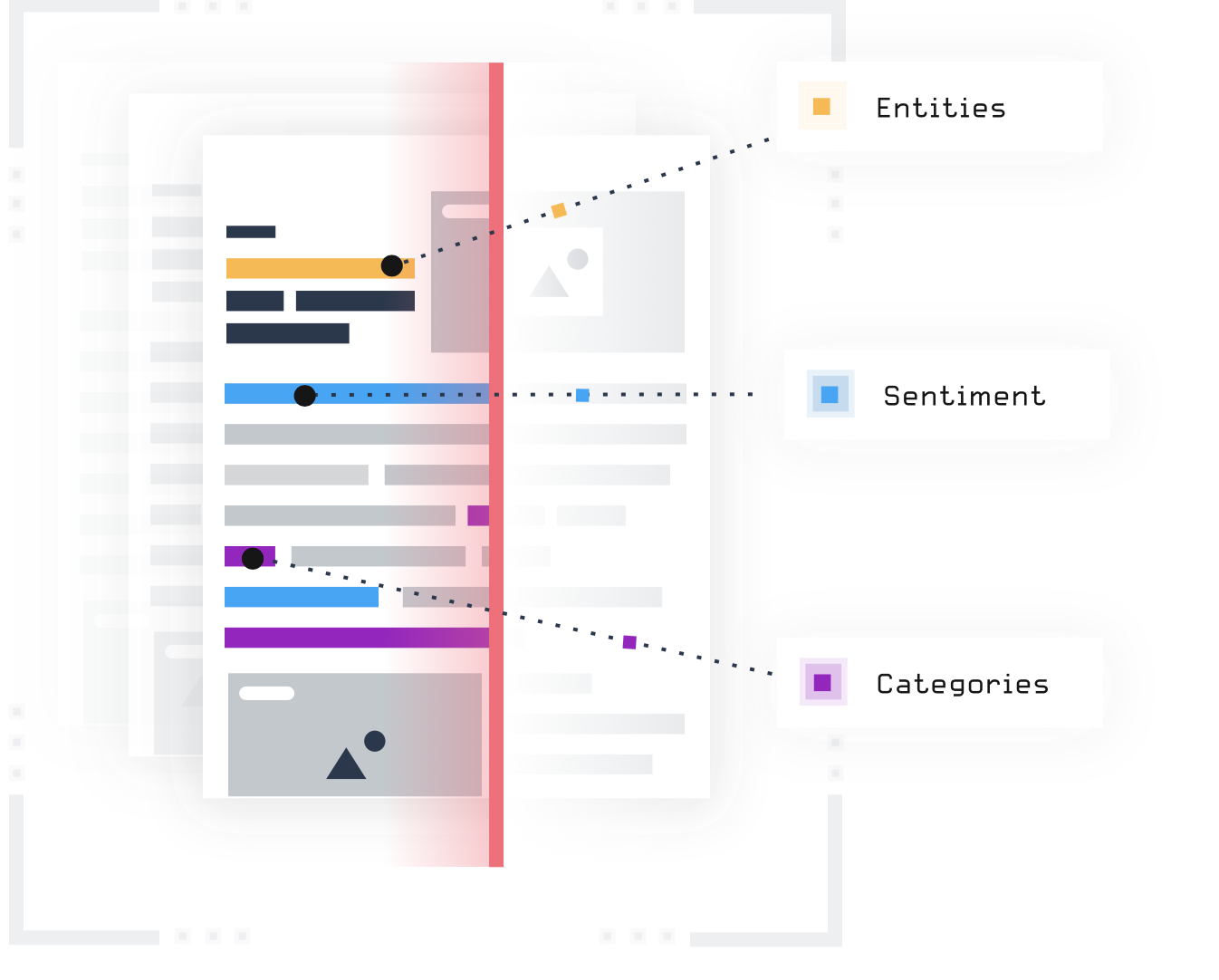
It does this by automatically identifying a number of datapoints, like entities (people, places, companies, concepts, products etc), news categories (over 2,600 of them), and sentiment (positive, neutral, negative), as well as extracting a rich amount of metadata (location, timestamp, source, author etc). This means queries to our huge database can be refined to great detail, making sure you can find the news that matters to you.
We’ll learn more about this enrichment in a moment, but first a short introduction to AYLIEN’s humble star of the show - the story object.
AYLIEN’s Story Object
At the very heart of AYLIEN’s News API is the story object. Simply put, stories are articles and other media that have been ingested into the AYLIEN ecosystem and undergone our NLP enrichment process. These individual stories are then searchable using the Stories endpoint. Aggregations of these stories can also be queried using the Timeseries, Trends and Clusters endpoints. You can learn more about these in our other posts in this series.

Stories objects all utilise the same structure; they are nested JSON objects with fields that contain the unique story ID, title and of course body text of the article.
AYLIEN’s enrichment process also adds further datapoints:
Metadata Extraction
Key article information such as the publication date, geolocation, author and publisher are added to the story object as additional fields. This information is fundamental to limiting a query to a specific time, region or publisher.
Entity Extraction
People, places, companies, objects and concepts in the title and body text are identified by our models utilising DBPedia’s knowledge base and tagged with unique IDs, enabling enhanced, accurate search functionality and negating the need for complex boolean searches.
Learn more about the effectiveness of using entities instead of keywords here.
Categorization
AYLIEN’s NLP enrichment classifies news stories into news categories such as business, economics and finance, crime, politics, sport and entertainment to name but a few. In fact, we use two news taxonomies to help our users isolate the news types that really matter to them and can choose between utilising IPTC and IAB QAG models.
Our supported taxonomies are made up of categories and subcategories, or parent categories and child categories e.g. Football being a child category of Sport. This allows our uses to easily traverse categories and isolate the news domains they need.
Sentiment Analysis
In Media Monitoring, sentiment analysis is an invaluable tool for tracking brand sentiment, the success of campaigns, public relations and monitoring crises. It can act as the acid test for public opinion and serve as a vital indicator of how a subject is perceived.
Our models classify documents as having positive, negative or neutral sentiment. Watch this space though - soon we’ll be launching entity-level sentiment analysis (ELSA) to provide even more specific sentiment analysis.
Machine Translation
We use our own Machine Translation models to translate content published in languages other than English back to English. This allows us to apply the same analysis models, tags, and enrichments to multilingual content which means you get the same search, discovery and investigation capabilities you get on English content.
Story objects that contain non-English content will consequently include a translated version as well as the native language, as well as the afore-mentioned entity, category and sentiment enrichments.
Enhanced Search and Usage Capability
So - why does this all matter? By collating huge volumes of open and gated news content, applying our in-house machine translation and enriching documents with our NLP models, we turn fragmented, unstructured media into cohesive, organized data that’s easily searchable and readily processable. In short, we do all the heavy lifting so you don’t have to.
In the next blog in the series, we’ll look at how to refine your News API query to identify the news that matters to you.
This blog is part of a series, AYLIEN NEWS API: A Starter Guide for Python Users. You can view the Jupyter Notebook learner document here.
Other Blogs in the series:
Starter Guide 2: Refining Your News API Query
Starter Guide 3: How To Use The News API Timeseries Endpoint
Starter Guide 4: How To Use The News API Trends Endpoint
Starter Guide 5: Starter Guide 5: How to Use the News API Clusters Endpoint

Related Content
-
 General
General20 Aug, 2024
The advantage of monitoring long tail international sources for operational risk

Keith Doyle
4 Min Read
-
General
16 Feb, 2024
Why AI-powered news data is a crucial component for GRC platforms

Ross Hamer
4 Min Read
-
General
24 Oct, 2023
Introducing Quantexa News Intelligence
Ross Hamer
5 Min Read
Stay Informed
From time to time, we would like to contact you about our products and services via email.