Four members of our research team spent the past week at the Conference on Empirical Methods in Natural Language Processing (EMNLP 2017) in Copenhagen, Denmark. The conference handbook can be found here and the proceedings can be found here. The program consisted of two days of workshops and tutorials and three days of main conference. The conference was superbly organized, had a great venue, and a social event with fireworks.

Figure 1: Fireworks at the social event
With 225 long papers, 107 papers, and 9 TACL papers accepted, there was a clear uptick of submissions compared to last year. The number of long and short paper submissions to EMNLP this year was even higher than those at ACL for the first time within the last 13 years, as can be seen in Figure 2.
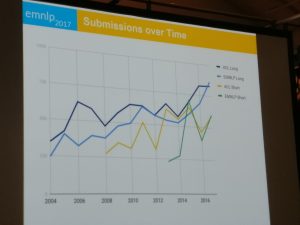
Figure 2: Long and short paper submissions at ACL and EMNLP from 2004-2017
In the following, we will outline our highlights and list some research papers that caught our eye. We will first list overall themes and will then touch upon specific research topics that are in line with our areas of focus. Also, we're proud to say that we had four papers accepted to the conference and workshops this year! If you want to see the AYLIEN team's research, check out the research sections of our website and our blog. With that said, let's jump in!
Exciting Datasets
Evaluating your approach on CoNLL-2003 or PTB is appropriate for comparing against previous state-of-the-art, but kind of boring. The two following papers introduce datasets that allow you to test your model in more exciting settings:
- Durrett et al. release a new domain adaptation dataset. The dataset evaluates models on their ability to identify products being bought and sold in online cybercrime forums.
- Kutuzov et al. evaluate their word embedding model on a new dataset that focuses on predicting insurgent armed groups based on geographical locations.
- While he did not introduce a new dataset, Nando de Freitas made the point during his keynote that the best environment for learning and evaluating language is simulation.

Figure 3: Nando de Freitas’ vision for AI research
Return of the Clusters
Brown clusters, an agglomerative, hierarchical clustering of word types based on contexts that was introduced in 1992 seem to come in vogue again. They were found to be particularly helpful for cross-lingual applications, while clusters were key features in several approaches:
- Mayhew et al. found that Brown cluster features were an important signal for cross-lingual NER.
- Botha et al. use word clusters as a key feature in their small, efficient feed-forward neural networks.
- Mekala et al.’s new document representations cluster word embeddings, which give it an edge for text classification.
- In his talk at the SCLeM workshop, Noah Smith cites the benefits of using Brown clusters as features for tasks such as POS tagging and sentiment analysis.

Figure 4: Noah Smith on the benefits of clustering in his invited talk at the SCLeM workshop
Distant Supervision
Distant supervision can be leveraged to collect large amounts of noisy training data, which can be useful in many applications. Some papers used novel forms of distant supervision to create new corpora or to train a model more effectively:
- Lan et al. use urls in tweets to collect a large corpus of paraphrase data. Paraphrase data is usually hard to create, so this approach facilitates the process significantly and enables a continuously expanding collection of paraphrases.
- Felbo et al. show that training on fine-grained emoji detection is more effective for pre-training sentiment and emotion models. Previous approaches primarily pre-trained on positive and negative emoticons or emotion hashtags.
Data Selection
The current generation of deep learning models is excellent at learning from data. However, we often do not pay much attention to the actual data our model is using. In many settings, we can improve upon the model by selecting the most relevant data:
- Fang et al. reframe active learning as reinforcement learning and explicitly learn a data selection policy. Active learning is one of the best ways to create a model with as few annotations as possible; any improvement to this process is beneficial.
- Van der Wees et al. introduce dynamic data selection for NMT, which varies the selected subset of the training data between different training epochs. This approach has the potential to reduce the training time of NMT models at comparable or better performance.
- Ruder and Plank use Bayesian Optimization to learn data selection policies for transfer learning and investigate how well these transfer across models, domains, and tasks. This approach brings us a step closer towards gaining a better understanding of what constitutes similarity between different tasks and domains.
Character-level Models
Characters are nowadays used as standard features in most sequence models. The Subword and Character-level Models in NLP workshop discussed approaches in more detail, with invited talks on subword language models and character-level NMT.
- Schmaltz et al. find that character-based sequence-to-sequence models outperform word-based models and models with character convolutions for sentence correction.
- Ryan Cotterell gave a great, movie-inspired tutorial on combining the best of FSTs (cowboys) and sequence-to-sequence models (aliens) for string-to-string transduction. While evaluated on morphological segmentation, the tutorial raised awareness in an entertaining way that often the best of both worlds, i.e. a combination of traditional and neural approaches performs best.

Figure 5: Ryan Cotterell on combining FSTs and seq2seq models for string-to-string transduction
Word Embeddings
Research in word embeddings has matured and now mainly tries to 1) address deficits of word2vec, such as its ability of dealing with OOV words; 2) extend it to new settings, e.g. modelling the relations of words over time; and 3) understand the induced representations better:
- Pinter et al. propose an approach for generating OOV word embeddings by training a character-based BiLSTM to generate embeddings that are close to pre-trained ones. This approach is promising as it provides us with a more sophisticated way to deal with out-of-vocabulary words than replacing them with an token.
- Herbelot and Baroni slightly modify word2vec to allow it to learn embeddings for OOV words from few data.
- Rosin et al. propose a model for analyzing when two words relate to each other.
- Kutuzov et al. propose another model that analyzes how two words relate to each other over time.
- Hasan and Curry improve the performance of word embeddings on word similarity tasks by re-embedding them in a manifold.
- Yang et al. introduce a simple approach to learning cross-domain word embeddings. Creating embeddings tuned on a small, in-domain corpus is still a challenge, so it is nice to see more approaches addressing this pain point.
- Mimno and Thompson try to understand the geometry of word2vec better. They show that the learned word embeddings are positioned diametrically opposite of their context vectors in the embedding space.
Cross-lingual transfer
An increasing number of papers evaluate their methods on multiple languages. In addition, there was an excellent tutorial on cross-lingual word representations, which summarized and tried to unify much of the existing literature. Slides of the tutorial are available here.
- Malaviya et al. train a many-to-one NMT to translate 1017 languages into English and use this model to predict information missing from typological databases.
- Mayhew et al. introduce a cheap translation method for cross-lingual NER that only requires a bilingual dictionary. They even perform a case study on Uyghur, a truly low-resource language.
- Kim et al. present a cross-lingual transfer learning model for POS tagging without parallel data. Parallel data is expensive to create and rarely available for low-resource languages, so this approach fills an important need.
- Vulic et al. propose a new cross-lingual transfer method for inducing VerbNets for different languages. The method leverages vector space specialisation, an effective word embedding post-processing technique similar to retro-fitting.
- Braud et al. propose a robust, cross-lingual discourse segmentation model that only relies on POS tags. They show that dependency information is less useful than expected; it is important to evaluate our models on multiple languages, so we do not overfit to features that are specific to analytic languages, such as English.

Figure 6: Anders Søgaard demonstrating the similarities between different cross-lingual embedding models at the cross-lingual representations tutorial
Summarization
The Workshop on New Frontiers of Summarization brought researchers together to discuss key issues related to automatic summarization. Much of the research on summarization sought to develop new datasets and tasks:
- Katja Filippova (Google Research, Switzerland) gave an interesting talk on sentence compression and passage summarization for Q&A. She described how they went from syntax-based methods to Deep Learning.
- Volkse et al. created a new summarization corpus by looking for ‘TL;DR’ on Reddit. This is another example of a creative use of distant supervision, leveraging information that is already contained in the data in order to create a new corpus.
- Falke and Gurevych won the best resource paper award for creating a new summary corpus that is based on concept maps rather than textual summaries. The concept map can be explored using a graph-based document exploration system, which is available as a demo here.
- Pasunuru et al. use multi-task learning to improve abstractive summarization by leveraging entailment generation.
- Isonuma et al. also use multi-task learning with document classification in conjunction with curriculum learning.
- Li et al. propose a new task, reader-aware multi-document summarization, which uses comments of articles, along with a dataset for this task.
- Naranyan et al. propose another new task, split and rephrase, which aims to split a complex sentence into a sequence of shorter sentences with the same meaning, and also release a new dataset.
- Ghalandari revisits the traditional centroid-based method and proposes a new strong baseline for multi-document summarization.
Bias
Data and model-inherent bias is an issue that is receiving more attention in the community. Some papers investigate and propose methods to address the bias in certain datasets and evaluations:
- Chaganty et al. investigate bias in the evaluation of knowledge base population models and propose an importance sampling-based evaluation to mitigate the bias.
- Dan Jurasky gave a truly insightful keynote about his three year-long study analyzing the body camera recordings his team obtained from the Oakland police department for racial bias. Besides describing the first contemporary linguistic study of officer-community member interaction, he also provided entertaining insights on the language of food (cheaper restaurants use terms related to addiction, more expensive venues use language related to indulgence) and the challenges of interdisciplinary publishing.
- Dubossarsky et al. analyze the bias in word representation models and propose that recently proposed laws of semantic change must be revised.
- Zhao et al. won the best paper award for an approach using Lagrangian relaxation to inject constraints based on corpus-level label statistics. An important finding of their work is bias amplification: While some bias is inherent in all datasets, they observed that models trained on the data amplified its bias. While a gendered dataset might only contain women in 30% of examples, the situation at prediction time might thus be even more dire.
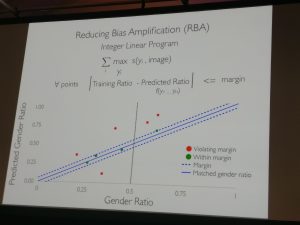
Figure 7: Zhao et al.’s proposed method for reducing bias amplification
Argument mining & debate analysis
Argument mining is closely related to summarization. In order to summarize argumentative texts, we have to understand claims and their justifications. This research area had the 4th Workshop on Argument Mining dedicated to it:
- Hidey et al. analyse the semantic types of claims (e.g. agreement, interpretation) and premises (ethos, logos, pathos) in the Subreddit Change My View. This is another creative use of reddit to create a dataset and analyze linguistic patterns.
- Wachsmut et al. presented an argument web search engine, which can be queried here.
- Potash and Rumshinsky predict the winner of debates, based on audience favorability.
- Swamy et al. also forecast winners for the Oscars, the US presidential primaries, and many other contests based on user predictions on Twitter. They create a dataset to test their approach.
- Zhang et al. analyze the rhetorical role of questions in discourse.
- Liu et al. show that argument-based features are also helpful for predicting review helpfulness.
Multi-agent communication
Multi-agent communication is a niche topic, which has nevertheless received some recent interest, notably in the representation learning community. Most papers deal with a scenario where two agents play a communicative referential game. The task is interesting, as the agents are required to cooperate and have been observed to develop a common pseudo-language in the process.
- Andreas and Klein investigate the structure encoded by RNN representations for messages in a communication game. They find that the mistakes are similar to the ones made by humans. In addition, they find that negation is encoded as a linear relationship in the vector space.
- Kottur et al. show in their best short paper that language does not emerge naturally when two agents are cooperating, but that they can be coerced to develop compositional expressions.

Figure 8: The multi-agent setup in the paper of Kottur et al.
Relation extraction
Extracting relations from documents is more compelling than simply extracting entities or concepts. Some papers improve upon existing approaches using better distant supervision or adversarial training:
- Liu et al. reduce the noise in distantly supervised relation extraction with a soft-label method.
- Zhang et al. publish TACRED, a large supervised dataset knowledge base population, as well as a new model.
- Wu et al. improve the precision of relation extraction with adversarial training.
Document and sentence representations
Learning better sentence representations is closely related to learning more general word representations. While word embeddings still have to be contextualized, sentence representations are promising as they can be directly applied to many different tasks:
- Mekala et al. propose a novel technique for building document vectors from word embeddings, with good results for text classification. They use a combination of adding and concatenating word embeddings to represent multiple topics of a document, based on word clusters.
- Conneau et al. learn sentence representations from the SNLI dataset and evaluate them on 12 different tasks.
These were our highlights. Naturally, we weren’t able to attend every session and see every paper. What were your highlights from the conference or which papers from the proceedings did you like most? Let us know in the comments below. 
Related Content
-
 General
General16 Feb, 2024
Why AI-powered news data is a crucial component for GRC platforms

Ross Hamer
4 Min Read
-
General
24 Oct, 2023
Introducing Quantexa News Intelligence
Ross Hamer
5 Min Read
-
 Product
Product15 Mar, 2023
Introducing an even better Quantexa News Intelligence app experience
Ross Hamer
4 Min Read
Stay Informed
From time to time, we would like to contact you about our products and services via email.