Adventures in Multi-Document Summarization: The Wikipedia Current Events Portal Dataset

In this post we give a brief overview of multi-document summarization (MDS) and some of our work in this area. We will explain:
Content overload is everywhere -- everything Kanye or Donald Trump does generates far too much content for anyone to consume (not that you’d necessarily want to anyway). In many cases, what we are looking for is a summary of the key events related to a topic. Multi-document summarization systems can produce such a summary. Multi-document summarization has potential applications wherever an overwhelming amount of related or overlapping documents appears, e.g. various news articles reporting the same event, multiple reviews of a product, or pages of search results in search engines.

In MDS, we have a cluster of related documents — think a bunch of news stories about the same event. We would like to condense the most important information from all of these documents into a single coherent summary.
For the rest of this post, we’ll focus on a specific use-case: given a cluster of news articles that revolve around one event, we want to generate a short summary containing the most important facts about the event.
Many academic research teams and companies have worked on this task, and there are various methods to create summaries.
Extractive summarization methods try to pick a small number of important sentences from the source documents and piece these snippets into a summary. The extractive approach has the advantage of preserving the facts in the original documents and producing summaries with grammatically correct and coherent sentences. However, these sentences can contain unnecessary information and combining sentences from different contexts can lead to an awkward reading flow. Extractive MDS is commonly treated as a ranking [1, 2] or combinatorial optimisation problem [3, 4].
Abstractive summarization on the other hand produces summaries by re-formulating or paraphrasing the source content. This has the advantage of achieving a desirable concise summary style with a better reading flow. While the grammaticality (i.e. fluency) of automatic abstractive summaries has improved in recent years, they still have a high risk of containing factual errors [5] which makes putting fully abstractive systems into real products risky. Abstractive summarization is usually treated as a sequence-to-sequence learning problem where encoder-decoder models are used, similar to machine translation. While there is plenty of work on using seq2seq models to summarize individual documents, only few works exist that apply these to MDS [6, 7, 8]. Apart from the seq2seq approach, there are also graph-based techniques for MDS that could be considered a hybrid between extractive and abstractive summarization [9, 10].
A major hurdle in designing multi-document summarization systems for news is the lack of appropriate large-scale datasets, making robust training and evaluation difficult. The commonly used DUC2004 dataset has only 50 clusters of documents, i.e. only 50 individual inputs for which we can generate a summary. The more recent MultiNews dataset is large on the other hand, but has quite verbose summaries, and only small clusters of mostly 2 or 3 documents. These datasets do not reflect real world scenarios with tens to hundreds of related documents requiring concise and informative summarization.
To create a better alternative for the use case we are interested in, we built the WCEP dataset which we presented in a paper at ACL 2020. It is based on the Wikipedia Current Events Portal (WCEP) where Wikipedia editors write concise summaries of important current events, usually in 1 or 2 sentences, and provide links to news articles as sources for each summary.
We constructed a dataset for automatic summarization from this resource as follows:
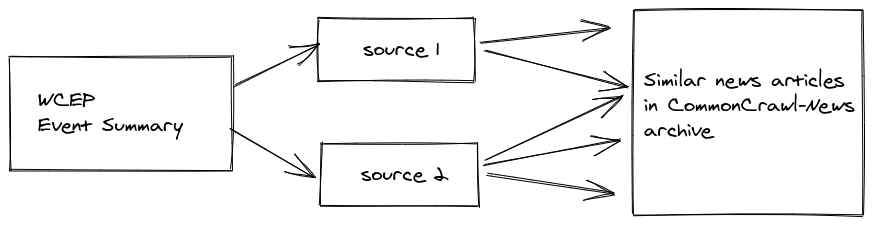
The WCEP dataset has about 10,000 examples, each consisting of a cluster of source articles and one ground-truth summary. The clusters are very large on average (up to 100) which mimics use cases where similar news articles from various sources are aggregated. Below is an example of a summary and some associated source articles:
|
Ground-truth summary |
| Emperor Akihito abdicates the Chrysanthemum Throne in favor of his elder son, Crown Prince Naruhito. He is the first Emperor to abdicate in over two hundred years, since Emperor Kökaku in 1817. |
|
Headlines of source articles (WCEP) |
|
Defining the Heisei Era: Just how peaceful were the past 30 years? |
|
As a New Emperor ls Enthroned in Japan, His Wife Won’t Be Allowed to Watch |
|
Sample headlines from CommonCrawl |
|
Japanese Emperor Akihito to abdicate after three decades on throne |
|
Japan’s Emperor Akihito says he is abdicating as of Tuesday at a ceremony, in his final official address to his people |
|
Akihito begins abdication rituals as Japan marks end of era |
You can download the dataset here. In this Colab Notebook you can inspect the dataset and run baselines and evaluation without installing anything locally. All of these only take a few lines:
from utils import read_jsonl_gz
from baselines import TextRankSummarizer
from evaluate import evaluate
from pprint import pprint
textrank = TextRankSummarizer()
dataset = list(read_jsonl_gz('WCEP/val.jsonl.gz'))
cluster = dataset[954]
articles = cluster['articles'][:10]
human_summary = cluster['summary']
automatic_summary = textrank.summarize(articles)
results = evaluate([human_summary], [automatic_summary])
print('Summary:')
print(automatic_summary)
print()
print('ROUGE scores:')
pprint(results)
Here we pick one cluster from the dataset (the example we gave earlier) and can see the extractive summary produced by the TextRank baseline and its ROUGE scores:
Summary:
New Emperor Naruhito ascended the throne on Wednesday after his father Akihito abdicated Tuesday night and became emperor emeritus.
When Akihito took the throne, he was emperor of a country with a population of 123 million people.
ROUGE scores:
{'rouge-1': {'f': 0.203, 'p': 0.189, 'r': 0.219},
'rouge-2': {'f': 0.0, 'p': 0.0, 'r': 0.0},
'rouge-l': {'f': 0.116, 'p': 0.108, 'r': 0.125}}
ROUGE is an evaluation metric that judges the quality of an automatically created summary by comparing it to one or more human-written reference summaries. This comparison is based on the overlap of individual words (unigrams) or longer sequences of words (e.g. bigrams, trigrams).
The ROUGE scores above would be considered somewhat low, i.e. not a high word overlap with the ground-truth summary. A ROUGE-1 score above 0.4 would be quite high for example. We can get the gist of the event from this automatic summary nevertheless - there are usually various acceptable solutions.
Many of the current state-of-the-art NLP results are achieved by fine-tuning large pre-trained models. In the case of text summarization, common pretrained models include BART and PEGASUS. These are pre-trained on generic tasks that encourage text understanding and generation, such as putting shuffled sentences back in order or predicting missing sentences. These models can be fine-tuned on specific summarization datasets, e.g. the CNN/DailyMail or XSum, which is much easier than training a model from scratch on these datasets.
However, It is not straightforward to use these models for MDS datasets since the model architectures are not designed to read multiple documents. To circumvent this issue, we developed an approach that we call Dynamic Ensemble Decoding (DynE) which we describe more in detail in this paper. The basic idea is to apply multiple instances of an encoder-decoder network to multiple source documents. At each decoding (word selection) step, each of these model instances predicts next-word probabilities based on a) its own (not-shared) input and b) the output generated so far, which is shared among instances. We pick the next word by ensembling the decisions of all instances.
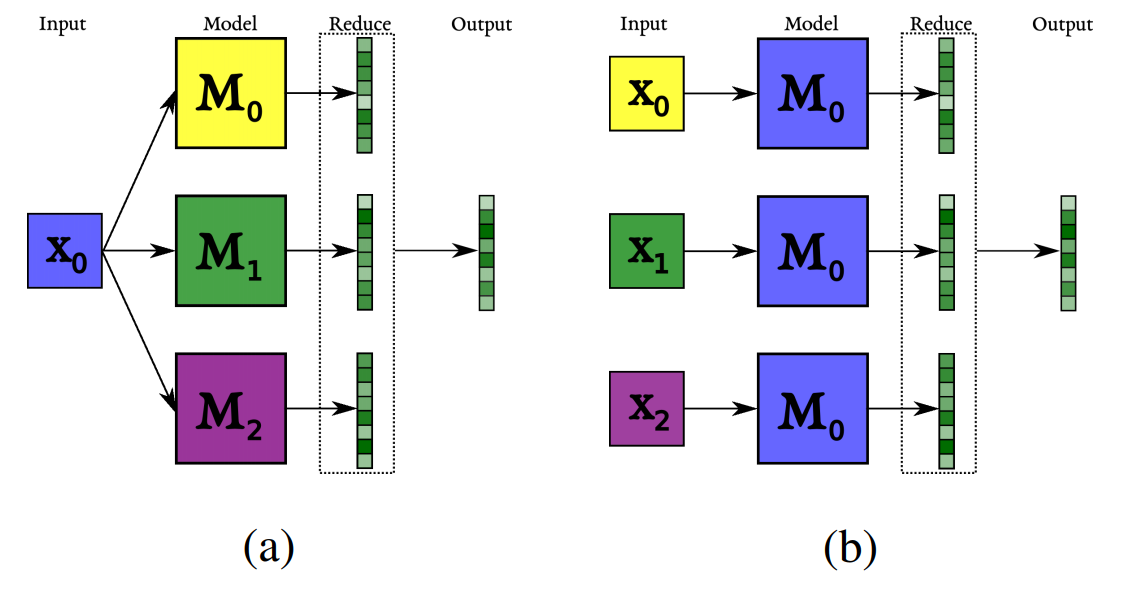
To apply this model to a specific dataset, all we need to do is fine-tune a pre-trained seq-to-seq model such as BART in a single-document summarization setting (note some off-the-shelf summarization models are already available, and these can just be used directly). Only at inference time, we ensemble model instances of different source documents.
To test this idea, we ran experiments on the WCEP, MultiNews and DUC2004 datasets. DynE provides the state-of-the-art performance on WCEP and also beat the (back-in-2020) state-of-the-art in MultiNews. This framework provides a simple and powerful baseline for abstractive multi-document summarisation. You can try it out here.
To recap, we gave an overview of multi-document summarization, and discussed the key differences between extractive and abstractive summarization in multi-document settings. We introduced WCEP, a large scale MDS dataset in the news domain, and we pointed readers to DynE, which is a strong abstractive MDS baseline that is simple to run and evaluate.
Because this problem is very relevant to many companies and researchers, we hope this post can help people get started diving into this super interesting area.

20 Aug, 2024

Keith Doyle
4 Min Read
16 Feb, 2024
Ross Hamer
4 Min Read
24 Oct, 2023
Ross Hamer
5 Min Read
From time to time, we would like to contact you about our products and services via email.