It is a strong indicator of today’s globalized world and rapidly growing access to Internet platforms, that we have users from over 188 countries and 500 cities globally using our Text Analysis and News APIs. Our users need to be able to understand and analyze what’s being said out there, about them, their products, services, or their competitors, regardless of the locality and the language used. Social media content on platforms like Twitter, Facebook and Instagram can provide unrivalled insights into customer opinion and experience to brands and organizations. However, as shown by the following stats, users post content in a multitude of languages on these platforms:
- Only about 39% of tweets posted are in English;
- Facebook recently reported that about 50% of its users speak a language other than English;
- Native platforms such as Sina Weibo and WeChat, where most of the content is written in a native language, are on the rise;
- 70% of active Instagram users are based outside the US.
A look at online review platforms such as Yelp and TripAdvisor, as well as various news outlets and blogs, reveals similar patterns regarding the variety of language used. Therefore, no matter if you are a social media analyst, or a hotel owner trying to gauge customer satisfaction, or a hedge fund analyst trying to analyze a foreign market, you need to be able to understand textual content in a multitude of languages.
The Challenge with Multilingual Text Analysis
Scaling Natural Language Processing (NLP) and Natural Language Understanding (NLU) applications – which form the basis of our Text Analysis and News APIs – to multiple human languages has traditionally proven to be difficult, mainly due to the language-dependent nature of preprocessing and feature engineering techniques employed in traditional approaches. However, Deep Learning-based NLP methods, which have gained a tremendous amount of growing attention and popularity over the last couple of years, have proven to bring a great amount of invariance to NLP processes and pipelines, including towards the language used in a document or utterance.

At AYLIEN we have been following the rise and the evolution of Deep Learning-based NLP closely, and our research team have been leveraging Deep Learning to tackle a multitude of interesting and novel problems in Representation Learning, Sentiment Analysis, Named Entity Recognition, Entity Linking and Generative Document Models, with multiple publications to date. Additionally, using technologies such as TensorFlow, Docker and Kubernetes, as well as software engineering best practices, our engineering team ensures this research is surfaced in our products by ensuring our proprietary models are performant and scalable, enabling us to serve millions of requests every day.
Multilingual Sentiment Analysis with AYLIEN
Today we’re excited to announce an early result of these efforts with the launch of the first version of our Deep Learning-based Sentiment Analysis models for short sentences which are now available for English, Spanish and German. Let’s explore a couple of examples and see these new capabilities in action:
Examples:
A Spanish tweet:
“Vamos!! Se ganó, valio la pena levantarse temprano, bueno el futbol todo lo vale :D”
Results:
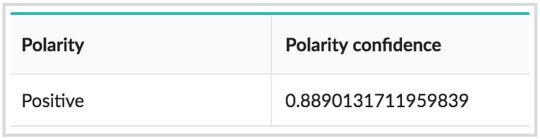
A German tweet:
“Lange wird es mein armes Handy nicht mehr machen :( Nach 5 Jahren muss ich mein Samsung Galaxy S 2 wohl bald aufgeben”
Results:
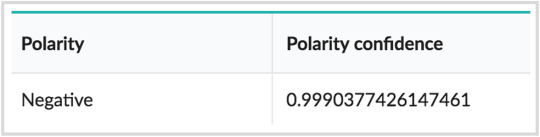
Try it out for yourself on our demo, or grab a free API key and an SDK to leverage these new models in your application.
How it Works
Our new models leverage the power of word embeddings, transfer learning and Convolutional Neural Networks to provide a simple, yet powerful end-to-end Sentiment Analysis pipeline which is largely language agnostic. Additionally, in contrast to more traditional machine learning models, this new model allows us to learn representations from large amounts of unlabeled data. This is particularly valuable for languages such as German where manually annotated data is scarce or expensive to generate, as it enables us to train sentiment models that leverage small amounts of annotated data in a language to great effect.
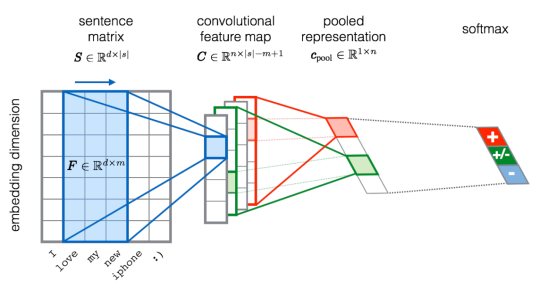
Source: Training Deep Convolutional Neural Network for Twitter Sentiment Classification by Severyn et al.
Next steps
Over the next couple of months, we will be continuing to work on improving these models as well as rolling out support for even more languages. Your feedback can be extremely helpful in shaping our roadmap, so if you have any thoughts, ideas or questions please feel free to reach out to us at hello@aylien.com. We are also excited about the new research that we’ve been doing on cross-lingual embeddings, which should make the process of multilingual Sentiment Analysis even easier. 
Related Content
-
 General
General20 Aug, 2024
The advantage of monitoring long tail international sources for operational risk

Keith Doyle
4 Min Read
-
General
16 Feb, 2024
Why AI-powered news data is a crucial component for GRC platforms

Ross Hamer
4 Min Read
-
General
24 Oct, 2023
Introducing Quantexa News Intelligence
Ross Hamer
5 Min Read
Stay Informed
From time to time, we would like to contact you about our products and services via email.