In recent times deep learning techniques have become more and more prevalent in NLP tasks; just take a look at the list of accepted papers at this year’s NAACL conference, and you can’t miss it. We’ve now completely moved away from traditional NLP approaches to focus on deep learning and how it can be leveraged in language problems, as successfully as it has in both image and audio recognition tasks.
One of these approaches that has seen great success and is backed by a wave of research papers and funding is the concept of word embeddings.
Word embeddings
For those of you who aren’t familiar with them, word embeddings are essentially dense vector representations of words.
Similar to the way a painting might be a representation of a person, a word embedding is a representation of a word, using real-valued numbers. They are an arrangement of numbers representing the semantic and syntactic information of words and their context, in a format that computers can understand.
Here’s a nice little primer you should read if you’re looking for a more in depth description: http://sebastianruder.com/word-embeddings-1/index.html
Word embeddings can be trained and used to derive similarities and relations between words. This means that by encoding each word as a small set of unique digits, say 100, 200 digits or more even that represent the word “mother” and another set of digits that represent “father” we can better understand the context of that word.

Source: https://www.tensorflow.org
Word vectors created through this process manifest interesting characteristics that almost look and sound like magic at first. For instance, if we subtract the vector of Man from the vector of King, the result will be almost equal to the vector resulting from subtracting Woman from Queen. Even more surprisingly, the result of subtracting Walked from Walking almost equates to that of Swam minus Swimming. These examples show that the model has not only learnt the meaning and the semantics of these words, but also the syntax and the grammar to some degree.
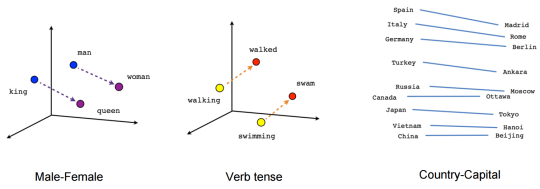
Relations between words according to word embeddings
Source: https://www.tensorflow.org
As our very own NLP Research Scientist, Sebastian Ruder, explains that “word embeddings are one of the few currently successful applications of unsupervised learning. Their main benefit arguably is that they don’t require expensive annotation, but can be derived from large unannotated corpora that are readily available. Pre-trained embeddings can then be used in downstream tasks that use small amounts of labeled data.”
Although word embeddings have almost become the de facto input layer in many NLP tasks, they do have some drawbacks. Let’s take a look at some of the challenges we face with word2vec, probably the most popular and commercialized model used today.
Word2vec Challenges
Inability to handle unknown or OOV words
Perhaps the biggest problem with word2vec is the inability to handle unknown or out-of-vocabulary (OOV) words.
If your model hasn’t encountered a word before, it will have no idea how to interpret it or how to build a vector for it. You are then forced to use a random vector, which is far from ideal. This can particularly be an issue in domains like Twitter where you have a lot of noisy and sparse data, with words that may only have been used once or twice in a very large corpus.
No shared representations at sub-word levels
There are no shared representations at sub-word levels with word2vec. For example, you and I might encounter a new word that ends in “less”, and from our knowledge of words that end similarly we can guess that it’s probably an adjective indicating a lack of something, like flawless or careless.
Word2vec represents every word as an independent vector, even though many words are morphologically similar, just like our two examples above.
This can also become a challenge in morphologically rich, and polysynthetic languages such as Arabic, German or Turkish.
Scaling to new languages requires new embedding matrices
Scaling to new languages requires new embedding matrices and does not allow for parameter sharing, meaning cross-lingual use of the same model isn’t an option.
Cannot be used to initialize state-of-the-art architectures
As explained earlier, pre-training word embeddings on weakly supervised or unsupervised data has become increasingly popular, as have various state-of-the-art architectures that take character sequences as input. If you have a model that takes character-based input, you normally can’t leverage the benefits of pre-training, which forces you to randomize embeddings.
Summary
So while the application of deep learning techniques like word embeddings and word2vec in particular have brought about great improvements and advancements in NLP, they are not without their flaws.
At AYLIEN, Representation Learning, the wider field word embeddings comes under, is an active area of research for us. Our scientists are actively working on better embedding models and approaches for overcoming some of the challenges we mentioned.
Stay tuned for some exciting updates over the next few weeks 😉.

Related Content
-
 General
General20 Aug, 2024
The advantage of monitoring long tail international sources for operational risk

Keith Doyle
4 Min Read
-
General
16 Feb, 2024
Why AI-powered news data is a crucial component for GRC platforms

Ross Hamer
4 Min Read
-
General
24 Oct, 2023
Introducing Quantexa News Intelligence
Ross Hamer
5 Min Read
Stay Informed
From time to time, we would like to contact you about our products and services via email.