At the end of last month, Facebook’s valuation dropped by $119 billion in the space of a couple of hours, which is the largest drop in the market valuation of a company in a single day ever. This drop was caused by investors dumping Facebook stock over the course of a quarterly earnings call from the company, where some disappointing figures were announced.
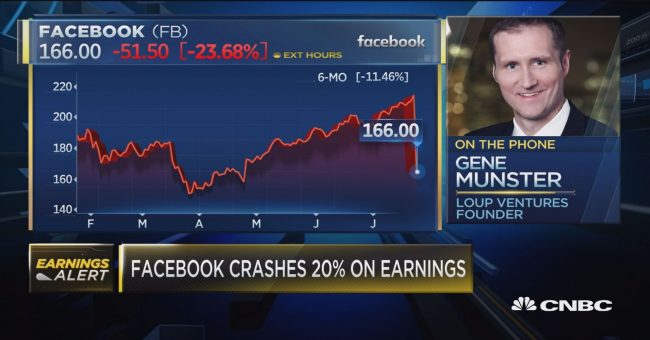
Events like this are a good time to see how Natural Language Processing can help us keep abreast of important news stories as they are breaking. Our News API monitors tens of thousands of news sources, analyzes new stories from them as they are published, and indexes them in a vast, live database that we can easily query. In this blog, we’re going to use the News API to see what Natural Language Processing could have told us about Facebook's tumbling share price as the call was taking place. Specifically, we’re going to:
- See how much the media was publishing about the earnings call, and how the story volume fluctuated as new information was relayed in this call.
- Watch how the sentiment changed over this period
- Find out what entities were being mentioned in coverage of the call, and what the sentiment was toward each one.
How much was published about the earnings call?
You can see two spikes in the volume of stories being published about Facebook: one in the hour of 4PM EST, while the earnings call was taking place, and a larger one in the hour of 10AM the following morning, after the New York Stock Exchange opened to Facebook’s plummeting share price.
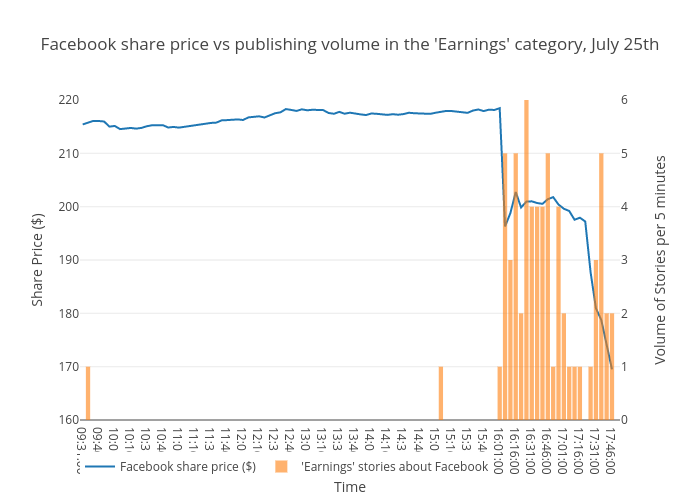
These spikes in mentions certainly are interesting and they clearly highlight the extent and speed of the media reaction to the Facebook earnings call. Using the News API, however, we can dig in deeper and get more granular insights. So first let’s look closer at how Facebook’s share price fell in after-hours trading during the earnings call. You can see that it tumbled in two noticeable drops, a little over an hour apart:
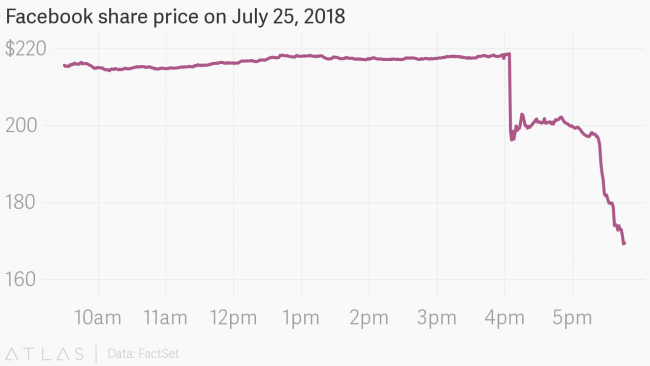
The first drop shaved 9% off the share price and occurred just after 4PM, at the beginning of the earnings call when slides were shared with investors and analysts showing the company had missed its earnings projections. After the share price had stabilized for about an hour, the second drop brought the loss to over 20%. This was during the question and answer section of the call when Facebook’s CFO warned that the dip in growth would continue into the next two quarters.
Did the News API detect a spike in stories during the earnings call?
While this call was taking place, journalists were reporting the announcements in real-time, and since the News API gathers, analyzes, and indexes tens of thousands of important sources all around the globe in real time, we can see what was being published as the call was taking place. To make sense of this content, the News API categorizes every story by two taxonomies - IAB-QAG and IPTC. We recently upgraded our IPTC model, so the News API can recognize some pretty granular topics. For example, one of the categories that the News API will recognize is earnings, a subcategory of company information. So using the Time Series endpoint, we looked into how many stories the News API stories categorized as being about earnings and containing 'Facebook' in the title on the day of the earnings call, and grouped the results into 15-minute blocks. You can see a clear correlation between the share price and publishing volume:
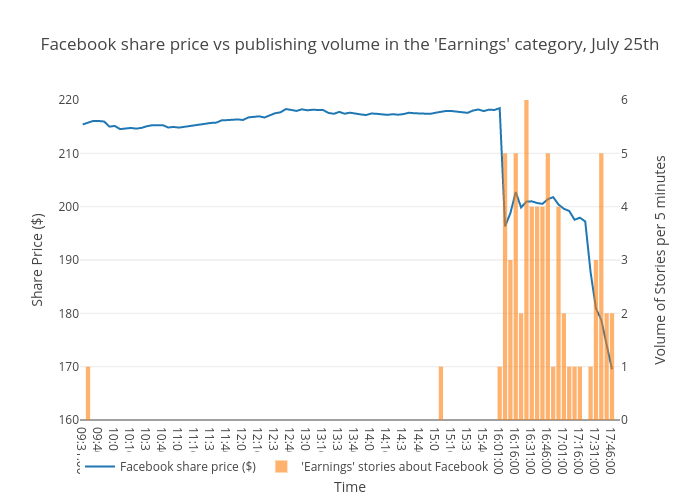
What was the sentiment of the coverage of the share price?
To get a more detailed look at the press coverage of the earnings call, we searched for the volume of stories being published with ‘Facebook’ in the title that the News API identified as being about ‘earnings’. You can see that coverage spikes in the fifteen minutes after the call begins, and turns overwhelmingly negative.
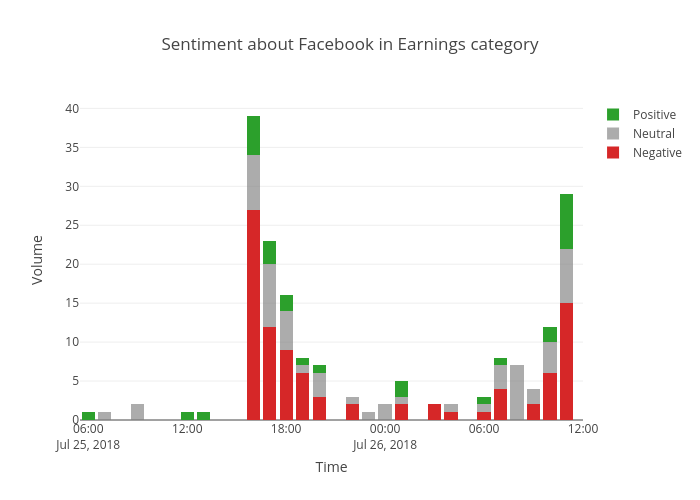
What can Entity-level Sentiment Analysis tell us about the coverage of the share price?
Once again, we can dig deeper into these stories. We looked into the stories about the earnings call and used our Entity-level Sentiment Analysis endpoint, which detects the sentiment expressed about every entity mentioned in a piece of text. Although the endpoint detected around 450 separate entities being talked about in the text, we’re going to show you the ten most-mentioned entities in the stories. You can see that the Cambridge Analytica scandal still garners the most negative coverage, but other than that, it’s Facebook and NASDAQ that are both the most-mentioned and most negatively mentioned entity.
EntityStories mentioningAverage polarityFacebook533-0.35NASDAQ139-0.24Cambridge Analytica120-0.50Market Capitalization1160.01Wall Street100-0.03Mark Zuckerberg95-0.05Amazon940.07European Union820.09Europe81-0.03Instagram650.31
You can also see that Instagram was the only entity to be mentioned positively, due to the announcement in the call that the product was Facebook’s best performing product over the quarter. So in this case, if our media monitoring solution uses the News API to monitor the ‘earnings’ IPTC category for spikes in volume, it will spot important events related to seasonal earnings calls as they happen. Additionally, we can use Entity-level Sentiment Analysis to get an understanding of what is causing the spike in coverage.

Related Content
-
 General
General20 Aug, 2024
The advantage of monitoring long tail international sources for operational risk

Keith Doyle
4 Min Read
-
General
16 Feb, 2024
Why AI-powered news data is a crucial component for GRC platforms

Ross Hamer
4 Min Read
-
General
24 Oct, 2023
Introducing Quantexa News Intelligence
Ross Hamer
5 Min Read
Stay Informed
From time to time, we would like to contact you about our products and services via email.