Artificial Intelligence and Machine Learning play a bigger part in our lives today than most people can imagine. We use intelligent services and applications every day that rely heavily on Machine Learning advances. Voice activation services like Siri or Alexa, image recognition services like Snapchat or Google Image Search, and even self driving cars all rely on the ability of machines to learn and adapt. If you’re new to Machine Learning, it can be very easy to get bogged down in buzzwords and complex concepts of this dark art. With this in mind, we thought we’d put together a quick introduction to the basics of Machine Learning and how it works. Note: This post is aimed at newbies - if you know a Bayesian model from a CNN, head on over to the research section of our blog, where you’ll find posts on more advanced subjects.
So what exactly is Machine Learning?
Machine Learning refers to a process that is used to train machines to imitate human intuition - to make decisions without having been told what exactly to do. Machine Learning is a subfield of computer science, and you’ll find it defined in many ways, but the simplest is probably still Arthur Samuel’s our definition from 1959: “Machine Learning gives computers the ability to learn without being explicitly programmed”. Machine Learning explores how programs, or more specifically algorithms, learn from data and make predictions based on it. These algorithms differ from traditional programs by not relying on strict coded instruction, but by making data-driven, informed predictions or decisions based on sample training inputs. Its applications in the real world are highly varied but the one common element is that every Machine Learning program learns from past experience in order to make predictions in the future. Machine Learning can be used to process massive amounts of data efficiently, as part of a particular task or problem. It relies on specific representations of data, or “features” in order to recognise something, similar to how when a person sees a cat, they can recognize it from visual features like its shape, its tail length, and its markings, Machine Learning algorithms learn from from patterns and features in data previously analyzed.
Different types of Machine Learning
There are many types of Machine Learning programs or algorithms. The most common ones can be split into three categories or types:
-
- 1. Supervised Machine Learning
-
- 2. Unsupervised Machine Learning
- 3. Reinforcement Learning
1. Supervised Machine Learning
Supervised learning refers to how a Machine Learning application has been trained to recognize patterns and features in data. It is “supervised”, meaning it has been trained or taught using correctly labeled (usually by a human) training data. The way supervised learning works isn’t too different to how we learn as humans. Think of how you teach a child: when a child sees a dog, you point at it and say “Look! A dog!”. What you’re doing here essentially is labelling that animal as a “dog”. Now, It might take a few hundred repetitions, but after a while the child will see another dog somewhere and say “dog,” of their own accord. They do this by recognising the features of a dog and the association of those features with the label “dog” and a supervised Machine Learning model works in much the same way. It’s easily explained using an everyday example that you have certainly come across. Let’s consider how your email provider catches spam. First, the algorithm used is trained on a dataset or list of thousands of examples of emails that are labelled as “Spam” or “Not spam”. This dataset can be referred to as “training data”. The “training data” allows the algorithm to build up a detailed picture of what a Spam email looks like. After this training process, the algorithm should be able to decide what label (Spam or Not spam) should be assigned to future emails based on what it has learned from the training set. This is a common example of a Classification algorithm - a supervised algorithm trained on pre-labeled data.
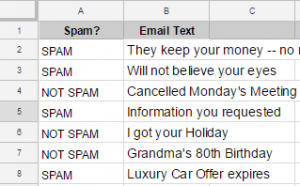
Training a spam classifier
2. Unsupervised Machine Learning
Unsupervised learning takes a different approach. As you can probably gather from the name, unsupervised learning algorithms don’t rely on pre-labeled training data to learn. Alternatively, they attempt to recognize patterns and structure in data. These patterns recognized in the data can then be used to make decisions or predictions when new data is introduced to the problem. Think back to how supervised learning teaches a child how to recognise a dog, by showing it what a dog looks like and assigning the label “dog”. Unsupervised learning is the equivalent to leaving the child to their own devices and not telling them the correct word or label to describe the animal. After a while, they would start to recognize that a lot of animals while similar to each other, have their own characteristics and features meaning they can be grouped together, cats with cats and dogs with dogs. The child has not been told what the correct label is for a cat or dog, but based on the features identified they can make a decision to group similar animals together. An unsupervised model will work in the same way by identifying features, structure and patterns in data which it uses to group or cluster similar data together. Amazon’s “customers also bought” feature is a good example of unsupervised learning in action. Millions of people buy different combinations of books on Amazon every day, and these transactions provide a huge amount of data on people’s tastes. An unsupervised learning algorithm analyzes this data to find patterns in these transactions, and returns relevant books as suggestions. As trends change or new books are published, people will buy different combinations of books, and the algorithm will adjust its recommendations accordingly, all without needing help from a human. This is an example of a clustering algorithm - an unsupervised algorithm that learns by identifying common groupings of data.
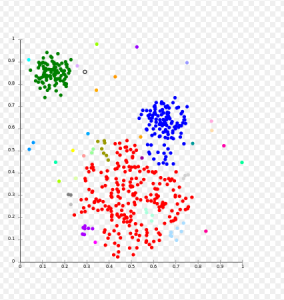
Clustering visualization
Supervised Versus Unsupervised Algorithms
Each of these two methods have their own strengths and weaknesses, and where one should be used over the other is dependent on a number of different factors: The availability of labelled data to use for training
-
- Whether the desired outcome is already known
-
- Whether we have a specific task in mind or we want to make a program for very general use
- Whether the task at hand is resource or time sensitive
Put simply, supervised learning is excellent at tasks where there is a degree of certainty about the potential outcomes, whereas unsupervised learning thrives in situations where the context is more unknown. In the case of supervised learning algorithms, the range of problems they can solve can be constrained by their reliance on training data, which is often difficult or expensive to obtain. In addition, a supervised algorithm can usually only be used in the context you trained it for. Imagine a food classifier that has only been trained on pictures of hot dogs - sure it might do an excellent job at recognising hotdogs in images, but when it’s shown an image of a pizza all it knows is that that image doesn’t contain a hotdog.
Unsupervised learning approaches also have many drawbacks: they are more complex, they need much more computational power, and theoretically they are nowhere near as understood yet as supervised learning. However, more recently they have been at the center of ML research and are often referred to as the next frontier in AI. Unsupervised learning gives machines the ability to learn by themselves, to extract information about the context you put them in, which essentially, is the core challenge of Artificial Intelligence. Compared with supervised learning, unsupervised learning offers a way to teach machines something resembling common sense.
3. Reinforcement Learning
Reinforcement learning is the third approach that you’ll most commonly come across. A reinforcement learning program tries to teach itself accuracy in a task by continually giving itself feedback based on its surroundings, and continually updating its behaviour based on this feedback. Reinforcement learning allows machines to automatically decide how to behave in a particular environment in order to maximize performance based off ‘reward‘ feedback or a reinforcement signal. This approach can only be used in an environment where the program can take signals from its surroundings as positive or negative feedback.
Imagine you’re programming a self-driving car to teach itself to become better at driving. You would program it to understand certain actions - like going off the road for example - is bad by providing negative feedback as a reinforcement signal. The car will then look at data where it went off the road before, and try to avoid similar outcomes. For instance, if the car sees a pattern like when it didn’t slow down at a corner it was more likely to end up driving off the road, but when it slowed down this outcome was less likely, it would slow down at corners more.
Conclusion
So this concludes our introduction to the basics of Machine Learning. We hope it provides you with some grounding as you try to get familiar with some of the more advanced concepts of Machine Learning. If you’re interested in Natural Language Processing and how Machine Learning is used in NLP specifically, keep an eye on our blog as we’re going cover how Machine Learning has been applied to the field. If you want to read some in-depth posts on Machine Learning, Deep Learning, and NLP, check out the research section of our blog. 
Related Content
-
 General
General20 Aug, 2024
The advantage of monitoring long tail international sources for operational risk

Keith Doyle
4 Min Read
-
General
16 Feb, 2024
Why AI-powered news data is a crucial component for GRC platforms

Ross Hamer
4 Min Read
-
General
24 Oct, 2023
Introducing Quantexa News Intelligence
Ross Hamer
5 Min Read
Stay Informed
From time to time, we would like to contact you about our products and services via email.