Natural Language Processing, Artificial Intelligence and Machine Learning are changing how content is discovered, analyzed and shared online. More recently, there has been a push to harness the power of Text Analytics to help understand and distribute content at scale. This is particularly evident with the popularity of recommendation engines and intelligent content analysis technologies like Outbrain and Taboola, who now have a presence on most content focused sites. Intelligent software and technological advancements allow machines to understand content as a human would. When we read a piece of text, we make certain observations about it. We understand what it’s about, we notice mentions of companies, people, places, we understand concepts present in it, we’re able to categorize it and if needed we could easily summarize it. All because we understand it and we can process it. Text Analysis and NLP techniques allow machines to do just that, understand and process text, but the main difference is, machines can work a lot faster than us humans.
But just how far can machines go in understanding a piece of content?
We won’t dwell too much on how the process works in this post, but instead we’ll to focus on what level of understanding a machine can extract from text by using the following news article as an example: http://www.reuters.com/article/2015/03/06/us-markets-stocks-idUSKBN0M21AP20150306 If you want to read more about how the process works and different approaches the Text Analysis you can download our Text Analysis 101 ebook here.
Extracting insight
When we read a news article, we might want to know what concepts it deals with, whether it mentions people, places, dates etc. We might need to determine whether it’s positive or negative, what’s the authors intent and whether it’s written subjectively or objectively. We do this almost subconsciously when we read text. NLP and AI allow machines to somewhat mimic this process by extracting certain things from text like Keywords, Entities, Concepts and Sentiment.
Entities
Content often contains mentions of people, locations, products, organizations etc. which we collectively call Named Entities. They can also contain values such as links, telephone numbers, email addresses, currency amounts, percentages and so on. Using statistical analysis and machine learning methods, these entities can be recognized and extracted from text as shown below.
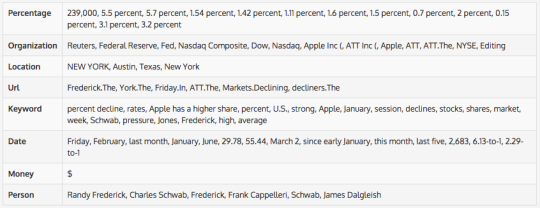
Concepts
Sometimes you wish to find entities and concepts based on information that exists in an external knowledge base, such as Wikipedia. Looking beyond statistical analysis methods and using a Linked Data-aware process machines can extract concepts from text. This allows for a greater understanding of topics present in text. Extracting concepts is a more intelligent and more accurate approach which gives a deeper understanding of text. These methods of analysis also allow machines to disambiguate terms and make decisions on how they interpret text, decisions like, is a mention of apple referring to the company or the fruit. Which is displayed as an example in the results below.
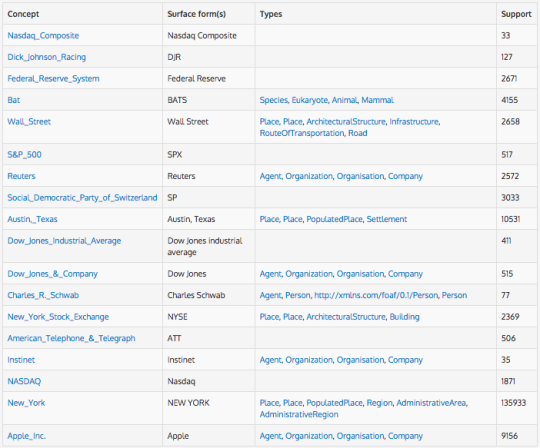
All of this information we can glean from text, showcases how machines understand it. However, it doesn’t need to stop there, with all of this information it’s possible to go a step further and start categorizing or classifying text.
Classification
Based on the meta-category of an article, we can easily understand, what a piece of content is about. As is shown in the results below from our sample article, classifying text can make it far easier to understand at a high level what a piece of content is about.

Classifying text means it is far easier to manage and sort large amounts of articles or documents without the need for human analysis which is often time consuming and inefficient.
Sentiment Analysis
Machines can even go as far as interpreting an author’s intent from analyzing text. Utilizing modern NLP techniques machines can determine whether a piece of text is written subjectively or objectively or whether it’s a positive, negative or neutral.

It’s also possible to process the insights to create something more, like a summarization of content for example.
Summarization
Sometimes articles and documents are just too long to consume, that’s where intelligent services like the automatic summarization of text can help. After analyzing a piece of content, it’s possible for machines to extract the key sentences or points conveyed and to display them as a consumable summary, like the one below.

These are some straightforward examples of the information machines can extract from text as part of the content analysis process. Our next post, will deal with what exactly, can be done with the information gleaned from text. We’ll look at real life use cases and examples of how automated Text Analysis is shaping how we deal with content online. 
Related Content
-
 General
General20 Aug, 2024
The advantage of monitoring long tail international sources for operational risk

Keith Doyle
4 Min Read
-
General
16 Feb, 2024
Why AI-powered news data is a crucial component for GRC platforms

Ross Hamer
4 Min Read
-
General
24 Oct, 2023
Introducing Quantexa News Intelligence
Ross Hamer
5 Min Read
Stay Informed
From time to time, we would like to contact you about our products and services via email.