I attended NAACL-HLT 2018 in New Orleans last week. I didn’t manage to catch as many talks and posters this time around (there were just too many inspiring people to talk to!), so my highlights and the trends I observed mainly focus on invited talks and workshops. Specifically, my highlights concentrate on three topics, which were prominent throughout the conference: Generalization, the Test-of-Time awards, and Dialogue Systems. For more information about other topics, you can check out the conference handbook and the proceedings. First of all, there were four quotes from the conference that particularly resonated with me (some of them are paraphrased):
- People worked on MT before the BLEU score. -- Kevin Knight It’s natural to work on tasks where evaluation is easy. Instead, we should encourage more people to tackle hard problems that are not easy to evaluate. These are often the most rewarding to work on.
- BLEU is an understudy. It was never meant to replace human judgement and never expected to last this long. -- Kishore Papineni, co-creator of BLEU, the most commonly used metric for machine translation No approach is perfect. Even the authors of landmark papers were aware their methods had flaws. The best we can do is provide a fair evaluation of our technique.
- We decided to sample an equal number of positive and negative reviews---was that a good idea? -- Bo Pang, first author of one of the first papers on sentiment analysis (7k+ citations) In addition to being aware of the flaws of our method, we should be explicit about the assumptions we make so that future work can either build upon them or discard them if they prove unhelpful or turn out to be false.
- I pose the following challenge to the community: we should evaluate on out-of-distribution data or on a new task. -- Percy Liang We never know how well our model truly generalizes if we just test it on data of the same distribution. In order to develop models that can be applied to the real world, we need to evaluate on out-of-distribution data or on a new task.
Percy Liang’s quote ties into one of the topics that received increasing attention at the conference: how can we train models that are less brittle and that generalize better?
Generalization
Over the last years, much of the research within the NLP community focused on improving LSTM-based models on benchmark tasks. At NAACL, it seemed that increasingly people were thinking about how to get models to generalize beyond the conditions during training, reflecting a similar sentiment in the Deep Learning community in general (a paper on generalization won the best paper award at ICLR 2017). One aspect is generalizing from few examples, which is difficult with the current generation of neural network-based methods. Charles Yang, professor of Linguistics, Computer Science and Psychology at the University of Pennsylvania put this in a cognitive science context. Machine learning and NLP researchers in the neural network era frequently like to motivate their work by referencing the remarkable generalization ability of young children. One piece of information that often is eluded, however, is that generalization in young children is also not without its errors, because it requires learning a rule and accounting for exceptions. For instance, when learning to count, young children still frequently make mistakes, as they have to balance rule-based generalization (for regular numbers such as sixteen, seventeen, eighteen, etc.) with memorizing exceptions (numbers such as fifteen, twenty, thirty, etc.). However, once a child can flawlessly count to 72, it can generalize to any new numbers. This magic number, 72, is given by the so-called tolerance principle, which prescribes that in order for a generalization rule to be productive, there can be at most N/ln(N) exceptions, where N is the total number of examples as can be seen in the Figure below. For counting, 72/ln(72) ≈ 17, which is exactly the number of exceptions until 72. Hitchhiker’s Guide to the Galaxy fans, however, need not be disappointed: in Chinese, the magic number is 42. Chinese only has 11 exceptions. As 42/ln(42) ≈ 11, Chinese children typically only need to learn to count up to 42 in order to generalize, which explains why Chinese children usually learn to count faster. [caption id="attachment_4833" align="aligncenter" width="650"]
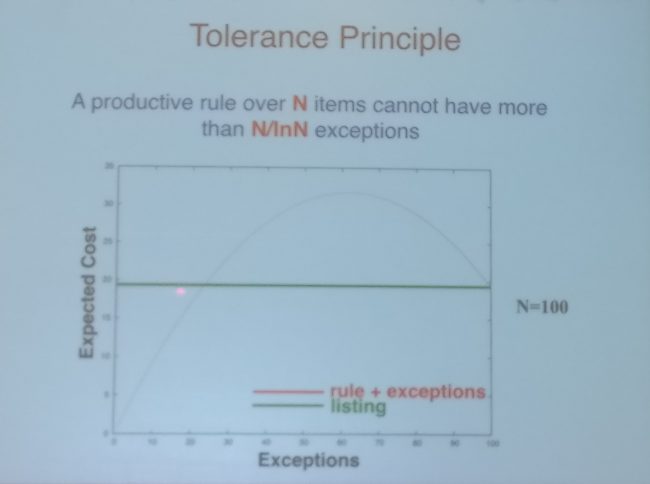
Figure 1: The Tolerance Principle[/caption] It is also interesting to note that even though young children can count up to a certain number, they can’t tell you, for example, which number is higher than 24. Only after they’ve learned the rule can they actually apply it productively. The tolerance principle implies that if the total number of examples covered by the rule is smaller, it is easier to incorporate comparatively more exceptions. While children can productively learn language from few examples, this indicates that for few-shot learning (at least in the cognitive process of language acquisition), big data may actually be harmful. Insights from cognitive science may thus help us in developing models that generalize better. The choice of the best paper of the conference, Deep contextualized word representations, also demonstrates an increasing interest in generalization. Embeddings from Language Models (ELMo) showed significant improvements over the state-of-the-art on a wide range of tasks as can be seen below. This---together with better ways to fine-tune pre-trained language models---reveals the potential of transfer learning for NLP. [caption id="attachment_4837" align="aligncenter" width="650"]
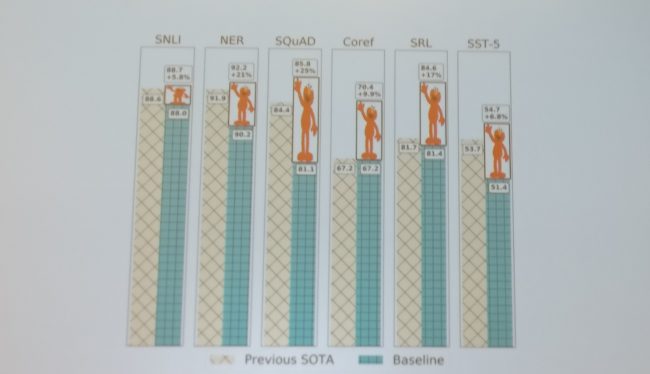
Figure 2: Improvements by ELMo on six diverse NLP tasks[/caption] Generalization was also the topic of the Workshop on New Forms of Generalization in Deep Learning and Natural Language Processing, which sought to analyze the failings of brittle models and propose new ways to evaluate and new models that would enable better generalization. Throughout the workshop, the room (seen below) was packed most of the time, which is both a testament to the prestige of the speakers and the community interest in the topic. [caption id="attachment_4836" align="aligncenter" width="650"]

Figure 3: The packed venue of the DeepGen Workshop[/caption] In the first talk of the workshop, Yejin Choi argued that natural language understanding (NLU) does not generalize to natural language generation (NLG): while pre-Deep Learning NLG models often started with NLU output, post-DL NLG seems less dependent on NLU. However, current neural NLG heavily depends on language models and neural NLG can be brittle; in many cases, baselines based on templates can actually work better. Despite advances in NLG, generating a coherent paragraph still does not work well and models end up generating generic, contentless, bland text full of repetitions and contradictions. But if we feed our models natural language input, why do they produce unnatural language output? Yejin identified two limitations of language models in this context. Language models are passive learners: in the real world, one can’t learn to write just by reading; and similarly, she argued, even RNNs need to “practice” writing. Secondly, language models are surface learners: they need “world” models and must be sensitive to the “latent process” behind language. In reality, people don’t write to maximize the probability of the next token, but rather seek to fulfill certain communicative goals. To address this, Yejin and collaborators proposed in an upcoming ACL 2018 paper to augment the generator with multiple discriminative models that grade the output along different dimensions inspired by Grice’s maxims. Yejin also sought to explain why there is a significant performance gaps between different NLU tasks such as machine translation and dialogue. For Type 1 or shallow NLU tasks, there is a strong alignment between input and output and models can often match surface patterns. For Type 2 or deep NLU tasks, the alignment between input and output is weaker; in order to perform well, a model needs to be able to abstract and reason, and requires certain types of knowledge, especially common sense knowledge. In particular, commonsense knowledge has somewhat fallen out of favour; past approaches, which were mostly proposed in the 80s, did not have access to a lot of computing power and were mostly done by non-NLP people. Overall, NLU traditionally focuses on understanding only “natural” language, while NLG also requires understanding machine language, which may be unnatural. Devi Parikh discussed generalization “opportunities” in visual question answering (VQA) and illustrated successes and failures of VQA models. In particular, VQA models are not very good at generalizing to novel instances; the distance of a test image from the k-nearest neighbours seen during training can predict the success or failure of a model with about 67% accuracy. Devi also showed that in many cases, VQA models do not even consider the entire question: in 50% of cases, only half the question is read. In particular, certain prefixes demonstrate the power of language priors: if the question begins with “Is there a clock…?”, the answer is “yes” 98% of the time; if the question begins with “Is the man wearing glasses…?”, the answer is “yes” 94% of the time. In order to counteract these biases, Devi and her collaborators introduced a new dataset of complimentary scenes, which are very similar but differ in their answers. They also proposed a new setting for VQA where for every question type, train and test sets have different prior distributions of answers. The final discussion with senior panelists (seen below) was arguably the highlight of the workshop; a summary can be found here. The main takeaways are that we need to develop models with inductive biases and that we need to do a better job of educating people on how to design experiments and identify biases in datasets. [caption id="attachment_4838" align="aligncenter" width="650"]

Figure 4: Panel discussion at the Generalization workshop (from left to right: Chris Manning, Percy Liang, Sam Bowman, Yejin Choi, Devi Parikh)[/caption]
Test-of-time awards
Another highlight of the conference was the test-of-time awards session, which highlighted persons and papers that had a huge impact on the field. At the beginning of the session, Aravind Joshi (see below), NLP pioneer and professor of Computer Science at the University of Pennsylvania, who passed away on December 31, 2017 was honored in touching epitaphs by close friends and people who knew him. The commemoration was a powerful reminder that research is about more than the papers we publish, but about the people we help and the lives we touch. [caption id="attachment_4839" align="aligncenter" width="650"]

Figure 5: Aravind Joshi[/caption] Afterwards, three papers (all published in 2002) were honored with test-of-time awards. For each paper, one of the original authors presented the paper and reflected on its impact. The first paper presented was BLEU: a Method for Automatic Evaluation of Machine Translation, which introduced the original BLEU metric, now commonplace in machine translation (MT). Kishore Papineni recounted that the name was inspired by Candide, an experimental MT system at IBM in the early 1990s and by IBM’s nickname, Big Blue, as all authors were at IBM at that time. Before BLEU, machine translation evaluation was cumbersome, expensive, and thought to be as difficult as training an MT model. Despite its huge impact, BLEU’s creators were apprehensive before its initial publication. Once published, BLEU seemed to split the community in two camps: those who loved it, and those who hated it; the authors hadn’t expected such a strong reaction. BLEU is still criticized today. It was meant as a corpus-level metric; individual sentence errors should be averaged out across the entire corpus. Kishore conceded that in hindsight, they made a few mistakes: they should have included smoothing and statistical significance testing; an initial version was also case insensitive, which caused confusion. In summary, BLEU has many known limitations and inspired many colorful variants. On the whole, however, it is an understudy (as the acronym BiLingual Evaluation Understudy implies): it was never meant to replace human judgement and---notably---was never expected to last this long. The second honored paper was Discriminative Training Methods for Hidden Markov Models: Theory and Experiments with Perceptron Algorithms by Michael Collins, which introduced the Structured Perceptron, one of the foundational and easiest to understand algorithms for general structured prediction. Lastly, Bo Pang looked back on her paper Thumbs up? Sentiment Classification using Machine Learning Techniques, which was the first paper of her PhD and one of the first papers on sentiment analysis, now an active research area in the NLP community. Prior to the paper, people had worked on classifying the subjectivity of sentences and the semantic orientation (polarity) of adjectives; sentiment classification was thus a natural progression. Over the years, the paper has accumulated more than 7,000 citations. One reason why the paper was so impactful was that the authors decided to release a dataset with it. Bo was critical of the sampling choices they made that “messed” with the natural distribution of the data: they capped the number of reviews of prolific authors, which was probably a good idea. However, they sampled an equal number of positive and negative reviews, which set the standard that many approaches later followed and is still the norm for sentiment analysis today. A better idea might have been to stay true to the natural distribution of the data. I found the test-of-time award session both insightful and humbling: we can derive many insights from traditional approaches and combining traditional with more or recent approaches is often a useful direction; at the same time, even the authors of landmark papers are critical of their own work and aware of its own flaws.
Dialogue systems
Another pervasive topic at the conference was dialogue systems. On the first day, researchers from PolyAI gave an excellent tutorial on Conversational AI. On the second day, Mari Ostendorf, professor of Electrical Engineering at the University of Washington and faculty advisor to the Sounding Board team, which won the inaugural Alexa Prize competition, shared some of the secrets to their winning socialbot. A socialbot in this context is a bot with which you can have a conversation, in contrast to a personal assistant that is designed to accomplish user-specified goals. A good socialbot should have the same qualities as someone you enjoy talking to at a cocktail party: it should have something interesting to say and show interest in the conversation partner. To illustrate this, an example conversation with the Sounding Board bot can be seen below. [caption id="attachment_4840" align="aligncenter" width="650"]
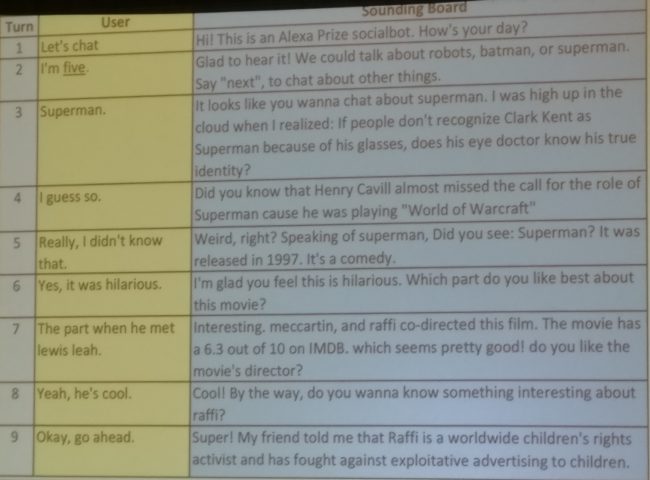
Figure 6: An example conversation with the Sounding Board bot[/caption] With regard to saying something interesting, the team found that users react positively to learning something new but negatively to old or unpleasant news; a challenge here is to filter what to present to people. In addition, users lose interest when they receive too much content that they do not care about. Regarding expressing interest, users appreciate an acknowledgement of their reactions and requests. While some users need encouragement to express opinions, some prompts can be annoying (“The article mentioned Google. Have you heard of Google?”). They furthermore found that modeling prosody is important. Prosody deals with modeling the patterns of stress and intonation in speech. Instead of sounding monotonous, a bot that incorporates prosody seems more engaging, can better articulate intent, communicate sentiment or sarcasm, express empathy or enthusiasm, or change the topic. In some cases, prosody is also essential for avoiding---often hilarious---misunderstandings: for instance, the Alexa’s default voice pattern for ‘Sounding Board’ sounds like ‘Sounding Bored’. Using a knowledge graph, the bot can have deeper conversations by staying “sort of on topic without totally staying on topic”. Mari also shared four key lessons that they learned working with 10M conversations:
Lesson #1: ASR is imperfect
While automatic speech recognition (ASR) has reached lower and lower word error rates in recent years, ASR is far from being solved. In particular, ASR in dialogue agents is tuned for short commands, not conversational speech. Whereas it can accurately identify for instance many obscure music groups, it struggles with more conversational or informal input. In addition, current development platforms provide developers with an impoverished representation of speech that does not contain segmentation or prosody and often misses certain intents and affects. Problems caused by this missing information can be seen below. [caption id="attachment_4841" align="aligncenter" width="650"]

Figure 7: Problems caused by missing prosody information and missing punctuation[/caption] In practice, the Sounding Board team found it helpful for the socialbot to behave similarly to attendees at a cocktail party: if the intent of the entire utterance is not completely clear, the bot responds to whatever part it understood, e.g. to a somewhat unintelligible “cause does that you’re gonna state that’s cool” it might respond “I’m happy you like that.” They also found that often, asking the conversation partner to repeat an utterance will not yield a much better result; instead, it is often better just to change the topic.
Lesson #2: Users vary
The team discovered something what might seem obvious but has wide-ranging consequences in practice: users vary a lot across different dimensions. Users have different interests, different opinions on issues, and a different sense of humor. Interaction styles, similarly, can range from terse to verbose (seen below), from polite to rude. Users can also interact with the bot in pursuit of widely different goals: they may seek information, intend to share opinions, try to get to know the bot, or seek to explore the limitations of the bot. Modeling the user involves both determining what to say as well as listening to what the user says. [caption id="attachment_4842" align="aligncenter" width="650"]

Figure 8: Interaction styles of talkative and terse users[/caption]
Lesson #3: It’s a wild world
There is a lot of problematic content and many issues exist that need to be navigated. Problematic content can consist of offensive or controversial material or sensitive and depressing topics. In addition, users might act adversarially and deliberately try to get the bot to produce such content. Examples of such behaviour can be seen below. Other users (e.g. such as those suffering from a mental illness) are in turn risky to deal with. Overall, filtering content is a hard problem. As one example, Mari mentioned that early in the project, the bot made the following witty observation / joke: “You know what I realized the other day? Santa Claus is the most elaborate lie ever told”. [caption id="attachment_4843" align="aligncenter" width="650"]

Figure 9: Adversarial user examples[/caption]
Lesson #4: Shallow conversations
As the goal of the Alexa Prize was to maintain a conversation of 20 minutes, in light of the current limited understanding and generation capabilities, the team focused on a dialog strategy of shallow conversations. Even for shallow conversations, however, switching to related topics can still be fragile due to word sense ambiguities. It is notable that among the top 3 Alexa Prize teams, Deep Learning was only used by one team and only for reranking. In total, a competition such as the Alexa Prize that brings academia and industry together is useful as it allows researchers to access data from real users at a large scale, which impacts the problems they choose to solve and the resulting solutions. It also teaches students about complete problems and real-world challenges and provides funding support for students. The team found it in particular beneficial someone from industry available to support the partnership, to provide advice on tools, and feedback on progress. On the other hand, privacy-preserving access to user data, such as prosody info for spoken language and speaker/author demographics for text and speech still needs work. For spoken dialog systems, richer speech interfaces are furthermore necessary. Finally, while competitions are great kickstarters, they nevertheless require a substantial engineering effort. Finally, in her keynote address on dialogue models, Dilek Hakkani-Tür, Research Scientist at Google Research, argued that over the recent years, chitchat systems and task-oriented dialogue systems have been converging. However, current production systems are essentially a walled garden of domains and only allow directed dialogue and limited personalization. Models have to be learned from developers using a limited set of APIs and tools and are hard to scale. At the same time, conversation is a skill even for humans. It is thus important to learn from real users, not from developers. In order to learn about users, we can leverage personal knowledge graphs learned from user assertions, such as “show me directions to my daughter’s school”. Semantic recall, i.e. remembering entities from previous user interactions, e.g. “Do you remember the restaurant we ordered Asian food from?” is important. Personalized natural language understanding can also leverage data from user’s device (in a privacy-preserving manner) and employ user modeling for dialogue generation. For learning from users, actions can be learned from user demonstration and/or explanation or from experience and feedback (mostly using RL for dialogue systems). In both cases, transcription and annotation are bottlenecks. A user can’t be expected to transcribe or annotate data; on the other hand, it is easier to give feedback after the system repeats an utterance. Generally, task-oriented dialogue can be treated as a game between two parties (see below): the seeker has a goal, which is fixed or flexible, while the provider has access to APIs to perform the task. The dialogue policy of the seeker decides the next seeker action. This is typically determined using “user simulators”, which are often sequence-to-sequence models. Most recently, hierarchical sequence-to-sequence models have been used with a focus on following the user goals and generating diverse responses. [caption id="attachment_4844" align="aligncenter" width="650"]

Figure 10: Task-oriented dialogue as a game[/caption] The dialogue policy of the provider similarly determines the next provider action, which is realized either via supervised or reinforcement learning (RL). For RL, reward estimation and policy shaping are important. Recent approaches jointly learn seeker and provider policies. End-to-end dialogue models with deep RL are critical for learning from user feedback, while component-wise training benefits from additional data for each component. In practice, a combination of supervised and reinforcement learning is best and outperforms both purely supervised learning and supervised learning with policy-only RL as can be seen below. [caption id="attachment_4845" align="aligncenter" width="650"]
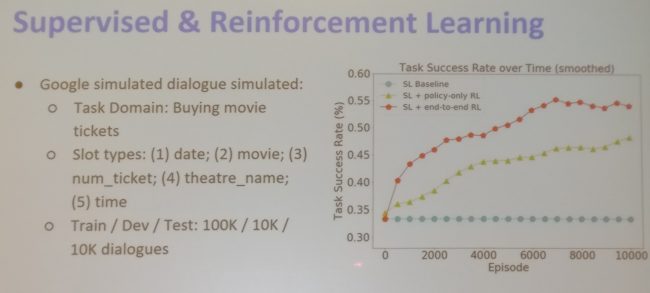
Figure 11: Supervised and reinforcement learning for dialogue modeling[/caption] Overall, the conference was a great opportunity to see fantastic research and meet great people. See you all at ACL 2018!

Related Content
-
 General
General20 Aug, 2024
The advantage of monitoring long tail international sources for operational risk

Keith Doyle
4 Min Read
-
General
16 Feb, 2024
Why AI-powered news data is a crucial component for GRC platforms

Ross Hamer
4 Min Read
-
General
24 Oct, 2023
Introducing Quantexa News Intelligence
Ross Hamer
5 Min Read
Stay Informed
From time to time, we would like to contact you about our products and services via email.