Today we’re announcing a major release of Enhanced Entities for the News API, a comprehensive update of our entity enrichment and search features, providing improved coverage and accuracy.
This release includes:
- A new entity recognition model (Entities V3)
- Enhanced search capabilities features
- Entity-level sentiment analysis features
Combined, these features provide an improved Entities experience to help you discover better quality data and business insights from our News API.
What's changed?
.png)
You can read more about using our V3 entity model in our common workflow section of our documentation: Working with Entities V3. You can also watch a demo of Enhanced Entities in action here.
What are entities?
Before we dive fully into what Enhanced Entities offer, let’s have a quick recap on what entities are, and why they’re important in this context. An entity is ‘a thing with a distinct and independent existence.’ In other words they are things like people, places, companies, products, and concepts that should, in theory, be easily identifiable when searching through the deluge of global daily news.
Problems arise when two or more entities have identical spellings but different meanings, e.g. apple the fruit and Apple the company. In this case a traditional keyword search is going to return results for all instances of that spelling, leaving you with a mass of irrelevant news articles to sift through, providing less accurate results that affect models and workflows. Further problems arise when a single entity is referred to in multiple surface forms, e.g. General Motors and GM. This can result in articles being missed entirely.
.png)
This problem is solved by leveraging AYLIEN’s natural language processing (NLP) technology. It provides accurate predictions about which entity is being referred to, in a process known as Named Entity Disambiguation. By contextualizing the entity with the rest of the article, and matching it to a knowledge base (Wikidata), AYLIEN can tell if the article is referring to e.g. Zurich the city, or Zurich the insurance group. As a result, entity-based searches substantially reduce noise by improving the accuracy and relevance of the news articles returned. Furthermore AYLIEN correctly recognizes the entity in each mention even when different surface forms are used, e.g. MetLife, MLIC, and Metropolitan Life Insurance Company, making sure that no mention is missed.
What are the benefits of Enhanced Entities?
Improved entity recognition and disambiguation
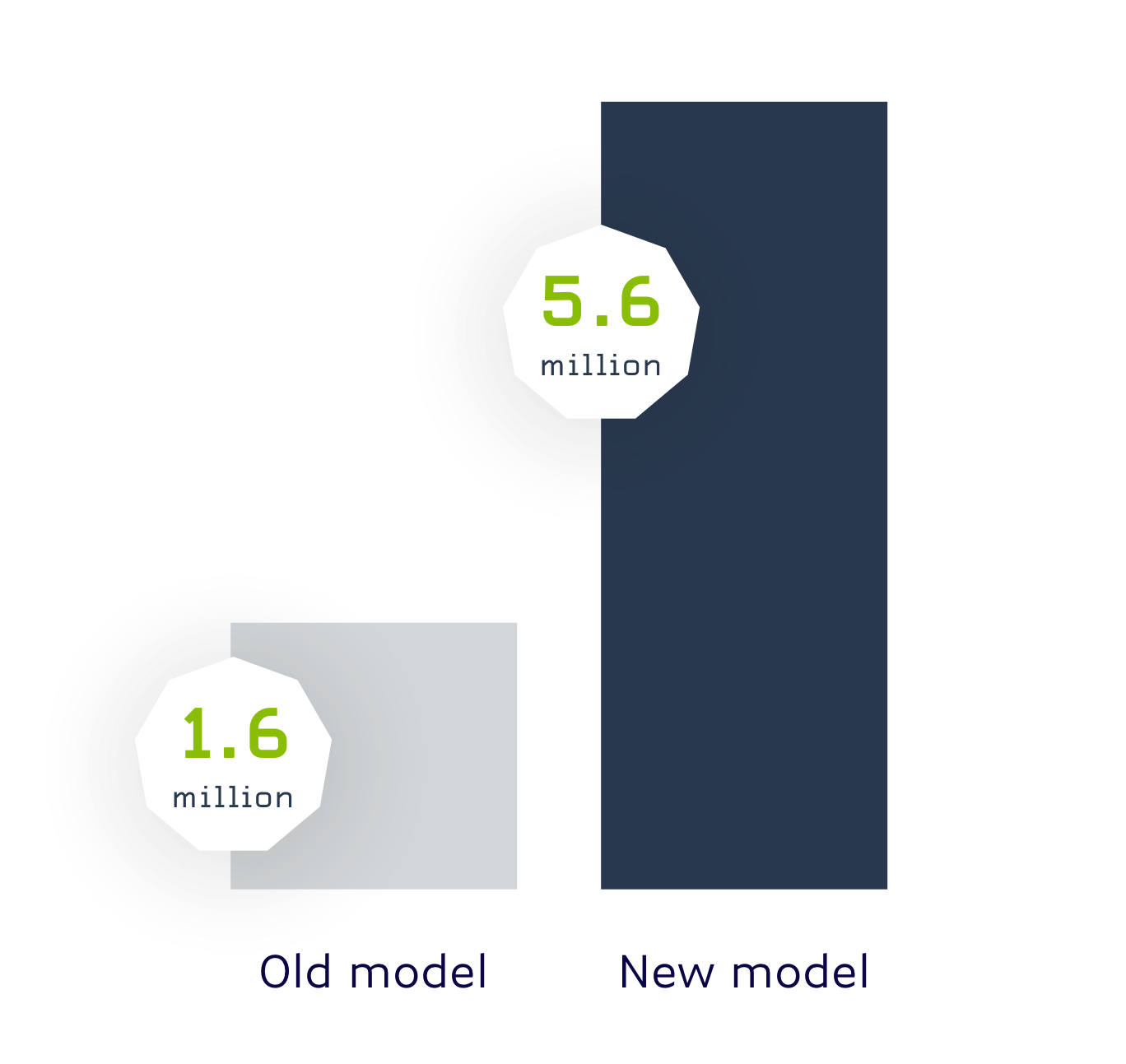
Our new entity model vastly improves the number of entities recognised from less than 2 million in the previous model, to around 5.6 million. We’ve also strengthened our performance in the financial services sector, where we have a recognition precision of 95% for S&P 500 and Russell 2000 company entities that were tested. Our model is also more accurate when tested against competing News API providers, where in some cases we out performed the competition by 65% in how many entities were recognised in a sample set of articles.
Let’s look at an example: Searching for articles that mention the payments company ‘Square’ in the title can be frustrating. Square is a common word and traditional searches will return a lot of noise. Enhanced Entities cuts out that noise, giving you articles like “Square to release a new payment feature in January”, instead of “Macy’s opens new store on Times Square”.
Enhanced search with entity types
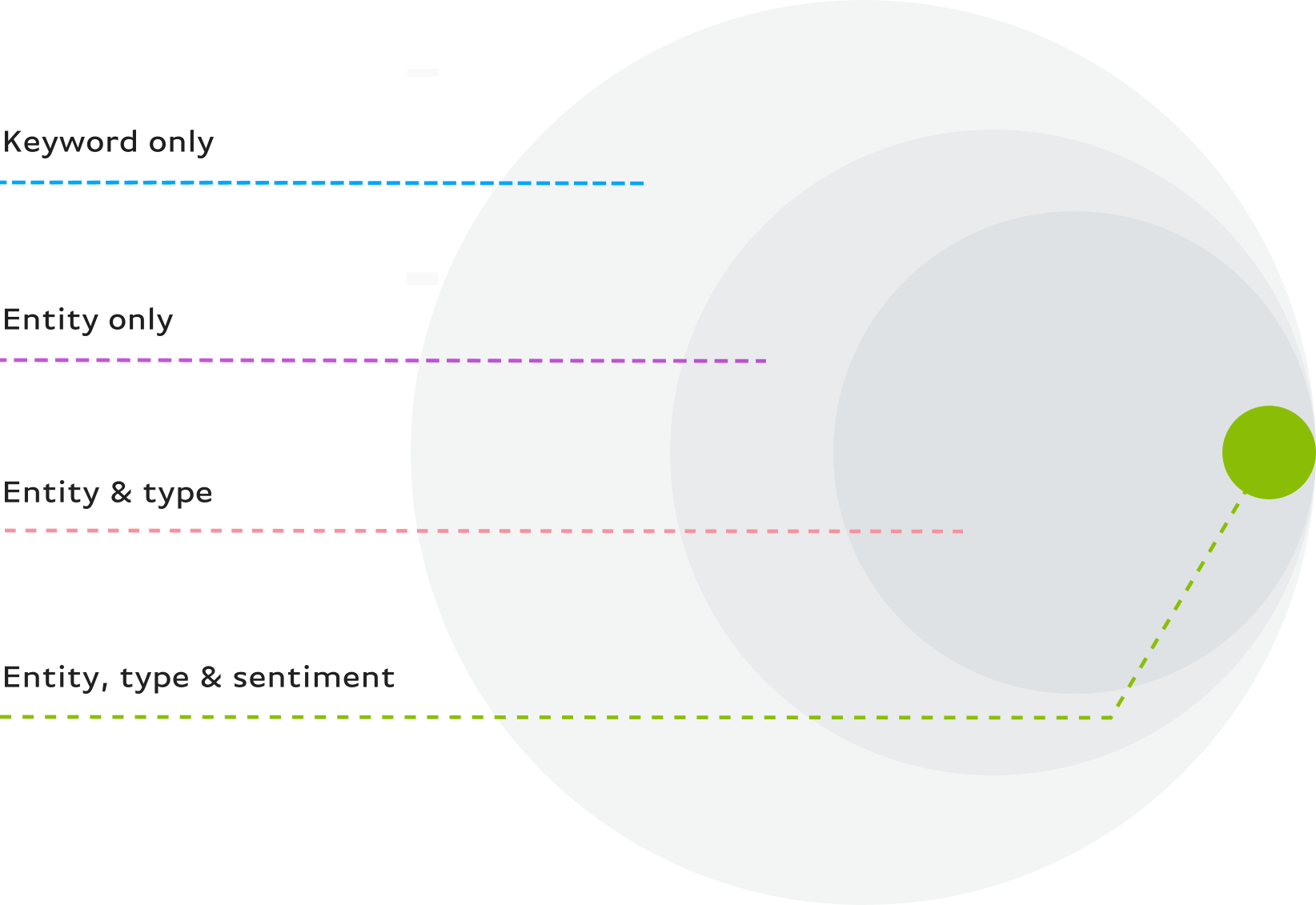
Enhanced search capabilities enables users to combine two or more entity-related parameters in a query to pinpoint the news that they’re looking for, reducing the noise of irrelevant results and false positives. It includes parameters for sentiment, type, and document element (title/body). We’ve also added the ability to identify an entity by querying its stock ticker or Wikipedia/Wikidata link to further increase accuracy.
Here’s a quick example: The more specific a search is, the more relevant your results are probably going to be. With that logic, combining entity parameters in Enhanced Entities will give you more accurate results. For example, searching for negative mentions of Elon Musk (type ‘human’) in articles that also have positive mentions of Tesla Motors (type ‘organization’) will hone in exactly on what you’re looking for.
Entity-level sentiment analysis (ELSA)

Every entity recognised in an article will now be given a sentiment prediction. Here’s how it works: Our NLP engine identifies entity candidates in each article, and then analyzes the full sentence it’s contained in to predict its sentiment polarity (positive, negative, or neutral). In cases where entities are mentioned multiple times, each mention will be assessed for sentiment and the average will be calculated across the title or body. A confidence score is also provided to show how much confidence the model has in the prediction.
Let’s use a simple example: Searching for articles that mention ‘Donald Trump’ with either a positive or negative sentiment may not be as easy as you think without ELSA. Relying on sentiment analysis at a document level could return an overall negative article, but mentions Trump in a positive way (or vice versa). Thankfully ELSA removes this ambiguity for more precise sentiment analysis.
Ultimately Enhanced Entities enables News API users to make more accurate searches to uncover the news that matters to them. You can read more about how to leverage our Enhanced Entities features in our documentation and migration guide, and watch a demo here. If you haven’t already you can sign up for a free trial of AYLIEN’s News API here.

Related Content
-
 General
General20 Aug, 2024
The advantage of monitoring long tail international sources for operational risk

Keith Doyle
4 Min Read
-
General
16 Feb, 2024
Why AI-powered news data is a crucial component for GRC platforms

Ross Hamer
4 Min Read
-
General
24 Oct, 2023
Introducing Quantexa News Intelligence
Ross Hamer
5 Min Read
Stay Informed
From time to time, we would like to contact you about our products and services via email.