Adieu, Text Analysis API

TL;DR - After 8 long years, we’re sunsetting our Text Analysis API. An API which made analysing textual content using Natural Language Processing fast, simple and accessible for thousands of developers and data scientists developing applications that required extracting insights from textual data at scale. Since we launched the API in 2014, the NLP market has gone through a truly major evolution, and as a result, our Text API has fulfilled its purpose and is ready to continue pumping blood (insights!) into the veins of our News Intelligence Platform to help companies draw valuable Risk and Market insights from news data.
It’s the Summer of 2013, and you’re a data scientist tasked with analysing responses to an online survey about customers’ recent hotel stays. Most of these responses are quantitative and structured–like whether the food was tasty, the location was good, and an overall satisfaction score between 1 and 10. You are well versed with storing, processing, and drawing insights from this type of data and you have a multitude of tools and knowledge at your disposal for accomplishing this. Easy peasy.
But hang on, at the very bottom of the survey, there are two large text input boxes where the hotel stayers can type in what they liked and disliked about the hotel in plain English. For instance, they might say “The food was bland” or “Jane at the front desk was really helpful”.
You let out a long “hmm”. You’re conflicted–you realise there are valuable insights trapped in those textual responses that could add a lot more context and meaning to the survey, and perhaps you can think of a few simple ways of extracting these insights. For example, you could compile a list of positive and negative adjectives, and count how many times each of those appear in the inputs. Sounds genius!
Excited by your genius invention, you scroll through the list of responses and eyeball the long list of reviews, looking for positive and negative adjectives. Very quickly, you come across the first edge case where your simple invention breaks down: In a review a customer has written “the seafood linguine wasn’t great at all”. Surely they weren’t happy with their linguine, so you can’t count this review as a positive just because it has “great” in it.
Puzzled by this, you open your browser and search for “how to anlayse the tone of textual reviews”. Quickly your eyes open wide and you realise there’s a name for exactly what you’re trying to achieve: “Sentiment Analysis”.
Unbeknownst to you, pockets of academics and researchers have been studying human language from a computational perspective for a long time. The field even has a name: “Computational Linguistics” (and sometimes an even fancier one, “Natural Language Processing”). Academics in this field have been applying statistical methods to human languages, looking for patterns between words, language fragments and grammatical constructs that could represent the semantics of documents. Effectively doing what you were doing with your simple lexicon-based approach (list of adjectives), but with more developed and nuanced techniques.
Thrilled by this discovery, you begin checking out a few of the search results for Sentiment Analysis. As you skim through them, you realise they are mostly research papers or academic publications in PDF format, or worse, behind a paywall. Your choices at this point are to read through several papers and try to implement a more advanced algorithm, or give up on analysing the textual bits in your survey responses altogether.
The story above describes the state of Natural Language Processing (NLP) in 2013. A small but growing academic community, lots of publications, but very little in terms of readily available software that “just worked”. There was no Text API, no spaCy, and no HuggingFace.
At AYLIEN, we were burnt by this pain too, and although we managed to acquire just enough knowhow to build our own NLP models, we realised that the need for NLP was going to be so significant, that thousands or perhaps millions of other developers were going to run into the same issue as us and the data scientist from our story. And we weren’t the only ones thinking that way. Indeed a couple of open source libraries such as NLTK and some commercial offerings such as AlchemyAPI (since acquired by IBM) existed around that time.
We formally began working on the Text API in January 2014 and by early April, we launched the first version and even enjoyed our 15 minutes of fame in the number 1 spot on Hacker News:

Soon thereafter we started getting hundreds and then thousands of sign-ups, which validated our hypothesis that this is an actual problem. Since its launch, the Text API saw 45,000+ sign-ups and we processed billions of documents of various types–news articles, reviews, social media updates, and more–for our customers.
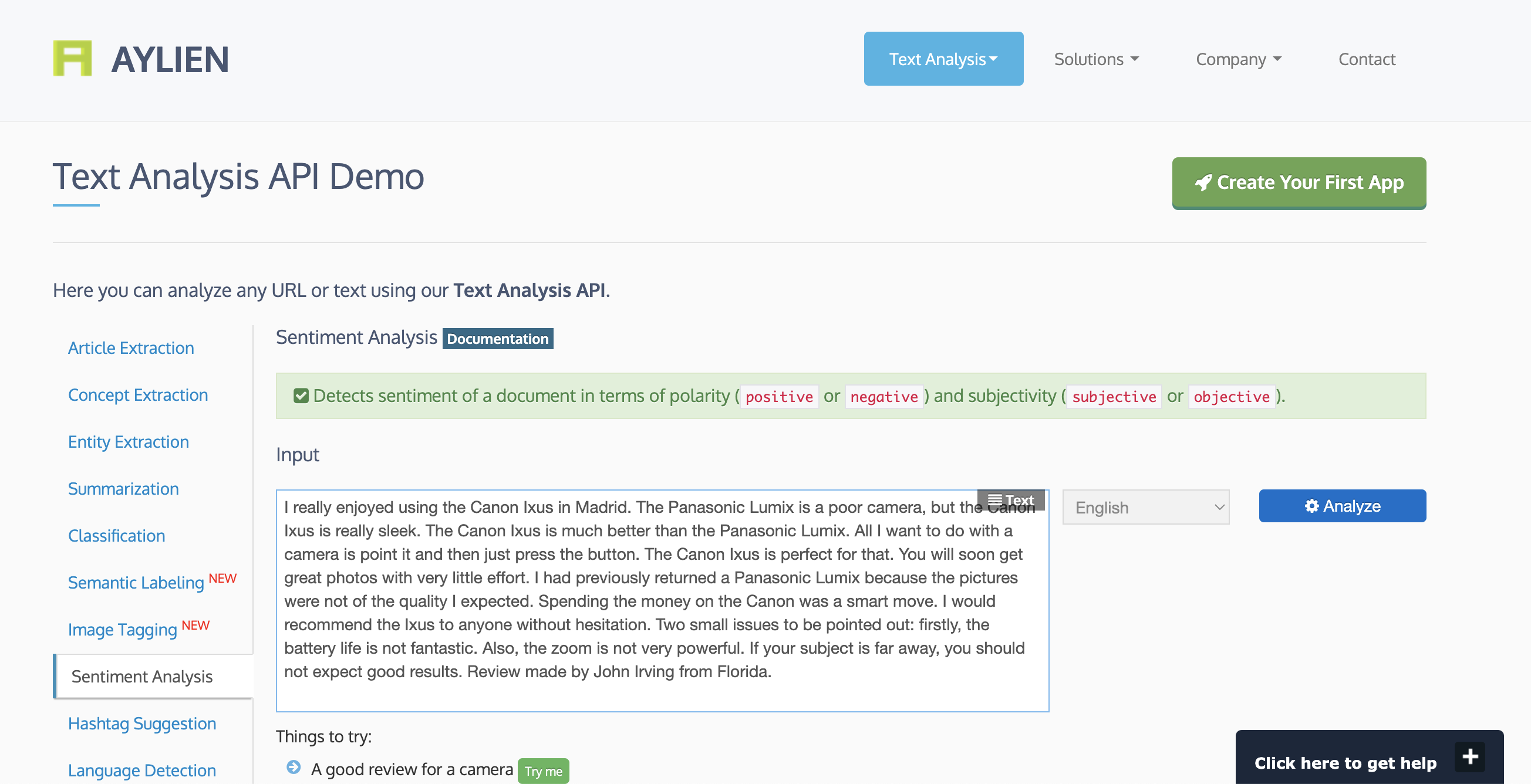
Over time we expanded the Text Analysis API in several ways:
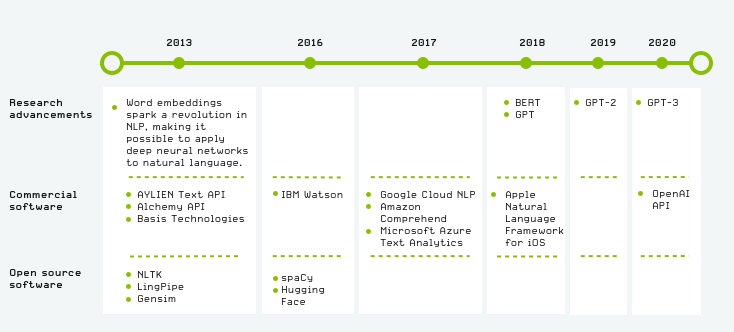
The short answer is: a lot. Each year since we launched the Text API has seen significant advancements in the field of Natural Language Processing, as well as a mass proliferation of relevant knowledge, tooling and datasets. Each of these leaps were so significant that they typically rendered the previous generation of tools and techniques obsolete. Between 2013 and 2022, NLP literally went from “bag-of-words and logistic regression”, to massive language models generating entire articles with high precision and cohesion.
This was a double-edged sword for us: While our vision for democratised access to NLP was coming true, competition among NLP providers became fiercer on an almost daily basis.
Below we’ve marked some of the key events during this period. Covering the entire history of NLP in this timeframe:
For us as a company, what was already an exciting problem space, became even more exciting as we learnt more about the use cases our customers had for the Text API. Anything from analysing articles for displaying contextually relevant ads, to understanding search queries in plain English to answer questions about the NFL fantasy league.
Amongst these various use cases, one that caught our attention the most was analysing news articles using NLP to extract business insights. A large portion of our customers in 2016 were using our API for this purpose, which is what inspired us to create and launch our News API – a platform for analysing large volumes of news articles using NLP to extract business insights.
We're deprecating our Text Analysis API :(. The sunsetting period will run for 30 days from 1st of September 2022 after which the Text Analysis API will be deprecated and will no longer be available.
For every user, the service will stop working from October 1st. This will mean the API will not be responsive and you won't be able to login to your Text Analysis dashboard to manage your account.
First things first, if you’re analyzing News content with the Text Analysis API then, of course, we recommend you join companies like Wells Fargo, S&P Global, and IBM who have chosen the News API to aggregate and analyze news content at scale. You can schedule a demo here.
If you’re analyzing other types of content like reviews, social commentary, or even longer-form documents we’d recommend the following services:
Commercial services:
Open source solutions:
The NLP landscape has changed dramatically in the last decade, and we are delighted to have played a role in pushing the field forward, and bringing document-based intelligence into thousands of applications. We wish to thank all our customers over the past 8 years. Also a special thank you to my colleagues at AYLIEN who were involved in the ideation and development of the Text API, as well as bringing it into the hands of tens of thousands of users.
Adieu, Text API.

20 Aug, 2024

Keith Doyle
4 Min Read
16 Feb, 2024
Ross Hamer
4 Min Read
24 Oct, 2023
Ross Hamer
5 Min Read
From time to time, we would like to contact you about our products and services via email.