If you’re new to News API and News Intelligence you may have come across some challenging terms and acronyms, especially if you’re not used to reading scientific definitions instead of plain and simple explanations.
To help you get a handle on this we‘ve put together a list of 10 common News API terms which we’ve broken down into easy to understand explanations, from the beginning of the process all the way to the end results.
Web Scraping
Web scraping (or just ‘scraping’) is the process of extracting data from a website. In a News Intelligence use case, it refers to articles from news websites (including data such as title, body text, metadata, and other information). Although it can be done manually, to do it effectively at scale the process really needs to be automated. A News API uses web scraping to aggregate millions of news articles every day from across the globe in real time that would otherwise be impossible.
Natural Language Processing (NLP)
NLP is a computer science field that focuses on interactions between computers and human language and a machine’s ability to understand or mimic the understanding of human language (also known as natural language understanding). News API takes news articles scraped from the web and applies NLP to them, bringing a wide variety of new possibilities to businesses, some of which are described below.
Structured/Unstructured Data
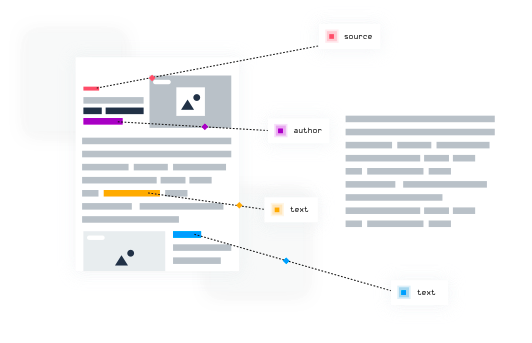
News articles are written in ‘human language’, which is referred to as unstructured data, i.e. not organized in a pre-defined manner. Structured data, however, is organized in a pre-defined, formatted manner and placed in storage e.g. a relational database. Converting unstructured data into structured data enables businesses to use it in models or gain insights in a much more efficient and effective way.
Information Extraction (IE)/Parsing
IE is the NLP process of automatically extracting structured information from unstructured sources, such as news articles from a website. Parsing analyzes the syntactic structure of the article and converts the unstructured data into a structured data format (e.g. title, author, text, source). Automating this process is exponentially more efficient and faster than manually doing it, which is a next to impossible task at scale.
Named Entity Recognition (NER)
NER is a subtask of IE, and is the process of locating and classifying entities in unstructured text, such as the names of people, organizations, places, products etc. NER identifies the context of an entity in relation to its surrounding text, and the entity can then be mapped to a knowledge base for disambiguation purposes.
Disambiguation
This is the ability to identify the meaning of words in context in a computational manner. A third party knowledge base, such as Wikipedia, can be used to cross-reference entities as part of this process. A simple example being for an algorithm to determine whether a reference to “apple” refers to the company or the fruit. The benefit of this is being able to filter out unwanted entities (e.g. the fruit, not the company) from your results.
Event Detection
Event Detection is a feature that uses a combination of enrichment data and other signals to group/cluster articles covering the same event or topic together in real time. It greatly improves the efficiency and accuracy of identifying news events/topics as they are breaking. Find out more about Event Detection here.
Sentiment Analysis

This is the use of NLP techniques to extract subjective information from a piece of text. i.e. predicting whether an author is being subjective or objective, positive, neutral, or negative. Sentiment analysis can be done at a document-level, i.e. whether a title and overall body text is positive, neutral, or negative. It can also be done at entity-level, for example if mentions of Joe Biden in an article are positive, neutral, or negative. (Note: this can also be referred to as Opinion Mining).
Time Series Analysis
A Time Series is a sequence of data points plotted over a specified time period. This makes it easy to analyze time-stamped data, allowing you to easily visualize the data in an understandable and meaningful format. For example, this is useful to gauge the fluctuation of story volume about a particular entity, or the number of stories about that entity that were positive and negative over time.
Trend Analysis
A Trend Analysis enables the identification of the most-frequent attributes of stories, e.g. the most frequently mentioned entities or keywords. Parameters can be set (e.g. time period), and a Trend Analysis will return the most mentioned entities or keywords in relation to the query.
Now that you are familiar with these terms, dive into our free trial of News API, or download one of our free datasets here.

Related Content
-
 General
General20 Aug, 2024
The advantage of monitoring long tail international sources for operational risk

Keith Doyle
4 Min Read
-
General
16 Feb, 2024
Why AI-powered news data is a crucial component for GRC platforms

Ross Hamer
4 Min Read
-
General
24 Oct, 2023
Introducing Quantexa News Intelligence
Ross Hamer
5 Min Read
Stay Informed
From time to time, we would like to contact you about our products and services via email.