If you’re relatively new to Machine Learning and it’s applications, you’ll more than likely have come across some pretty technical terms that are often difficult for the novice mathematician/scientist to get their head around.
Following on from a previous blog, (10 Common NLP Terms Explained for the Text Analysis Novice), we decided to put together a list of 10 Machine Learning terms which have been broken down in simple English, making them easier to understand. So, if you’re struggling to understand the difference between Supervised and Un-supervised Learning you’ll enjoy this post.
Machine Learning
A subfield of computer science and artificial intelligence (AI) that focuses on the design of systems that can learn from and make decisions and predictions based on data. Machine learning enables computers to act and make data-driven decisions rather than being explicitly programmed to carry out a certain task. Machine Learning programs are also designed to learn and improve over time when exposed to new data. Machine learning has been at the center of many technological advancements in recent years such as self-driving cars, computer vision and speech recognition systems.
Supervised Learning
Where a program is “trained” on a pre-defined dataset. Based off its training data the program can make accurate decisions when given new data. Example: Using a training set of human tagged positive, negative and neutral tweets to train a sentiment analysis classifier.
Unsupervised Learning
Where a program, given a dataset, can automatically find patterns and relationships in that dataset. Example: Analyzing a dataset of emails and automatically grouping related emails by topic with no prior knowledge or training which is also known as the practice of clustering.
Classification
A sub-category of Supervised Learning, Classification is the process of taking some sort of input and assigning a label to it. Classification systems are usually used when predictions are of a discrete, or “yes or no” nature. Example: Mapping a picture of someone to a male or female classification.
Regression
Another sub-category of supervised learning used when the value being predicted differs to a “yes or no” label as it falls somewhere on a continuous spectrum. Regression systems could be used, for example, to answer questions of “How much?” or “How many?”.
Decision Trees
A decision tree is a decision support tool that uses a tree-like graph or model of decisions and their possible consequences. A decision tree is also a way of visually representing an algorithm.
Example:
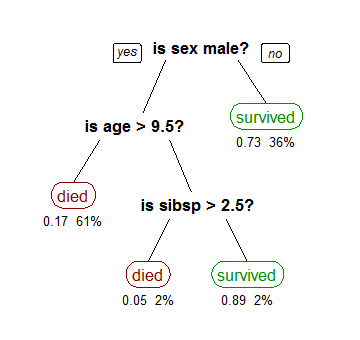
A decision tree showing survival of passengers on the Titanic (“sibsp” is the number of spouses or siblings aboard). Source: http://en.wikipedia.org/wiki/Decision_tree_learning
Generative Model
In probability and statistics, a Generative Model is a model used to generate data values when some parameters are hidden. Generative models are used in Machine Learning for either modeling data directly or as an intermediate step to forming a conditional probability density function. In other terms you model p(x,y) in order to make predictions (which can be converted to p(x|y) by applying the Bayes rule) as well as to be able to generate likely (x,y) pairs, which is widely used in Unsupervised Learning. Examples of Generative Models include Naive Bayes, Latent Dirichlet Allocation and Gaussian Mixture Model.
Discriminative Model
Discriminative Models or conditional models, are a class of models used in Machine Learning to model the dependence of a variable y on a variable x. As these models try to calculate conditional probabilities, i.e. p(y|x) they are often used in Supervised Learning. Examples include Logistic Regression, SVMs and Neural Networks.
Deep Learning
Quite a “hot topic” in recent years, deep learning refers to a category of machine learning algorithms that often use Artificial Neural Networks to generate models. Deep Learning techniques, for example, have been very successful in solving Image Recognition problems due to their ability to pick the best features, as well as to express layers of representation.
* Not to be mistaken with the neurons in your head.
Neural Networks or Artificial Neural Networks
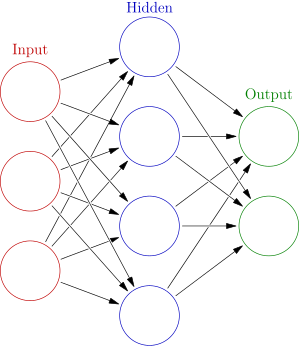
A simple Neural Network. Source: http://en.wikipedia.org/wiki/Artificial_neural_network
Inspired by biological neural networks, artificial neural networks are a network of interconnected nodes that make up a model. They can be defined as statistical learning models that are used to estimate or approximate functions that depend on a large number of inputs. Neural networks are usually used when the volume of inputs is far too large for standard machine learning approaches previously discussed.
Keep an eye out for more in the series and check out our Text Analysis 101 Series for detailed explanations of Text Analysis techniques.
Sign up for a free trial of
AYLIEN's News Intelligence platform
Related Content
-
 General
General20 Aug, 2024
The advantage of monitoring long tail international sources for operational risk

Keith Doyle
4 Min Read
-
General
16 Feb, 2024
Why AI-powered news data is a crucial component for GRC platforms

Ross Hamer
4 Min Read
-
General
24 Oct, 2023
Introducing Quantexa News Intelligence
Ross Hamer
5 Min Read
Stay Informed
From time to time, we would like to contact you about our products and services via email.